大三時因緣際會在國外留學時修了一堂人工智慧的課,從那時起就被機器學習的魅力深受吸引:即便對問題只有稍淺的domain knowledge,但是只要透過大量的資料去做訓練,依然可以使模型學會這些資料之間的關聯(當然對問題的domain knowledge懂得越多,對於資料的敏銳程度也會比較高;在feature selection時比較容易挑出好的feature,訓練時converge的速度也會比較快)。
回國後大四上要開始做畢業專題了,我找了幾個隊友以及一位從大一關係就還不錯專長是影像處理與訊號處理的教授討論方向,最後決定結合機器學習與影像辨識,做出一個概念性的自助餐菜色自動辨識結帳系統。

(將打完的自助餐放在攝影機下,系統即可辨識出菜色、結帳金額及卡路里)
本篇將以以下的順序紀錄整個畢業專題從無到有的過程:
- 需求與目標
- 自助餐菜色自動辨識結帳系統的開發構想
- 物件偵測的模型選擇(YOLOv3 vs Faster RCNN)
- 訓練資料
- 訓練模型
- 測試模型
- 自動計算所盛菜色的結帳金額
- 額外的附加功能:自動計算所盛菜色的卡路里
- 成品
- 口試當日的專題presentation影片
- 總結
需求與目標

(大排長龍的自助餐人潮)
每當用餐時間一到,學校學餐總是大排長龍。經過觀察,我們發現其中一家自助餐的bottleneck在於前台自助餐阿姨只有一個人,但同時要負責打菜與結帳兩項工作。
我們有問過阿姨有沒有考慮過要招一個工讀這樣可以分擔打菜與結帳的工作加快結帳的人潮,阿姨說如果讓工讀生負責打菜,她會擔心工讀生沒辦法掌握每樣菜色的份量;如果讓工讀生負責結帳,她也會擔心工讀生沒有辦法記下那麼多樣菜的價格。
因此在畢業專題上,我們幾人萌生了想要寫出一個能夠自動辨識自助餐菜色結並秀出總結帳金額的系統。這個系統能解決阿姨的concern,安心地聘一個工讀生負責結帳,這位工讀生也不需要記得所有菜色的價錢,只要將打好的餐盤放安裝在結帳台的攝影機下,系統就能夠自動算出結帳的總金額,工讀生再依照所秀出的金額收錢即可。
自助餐菜色自動辨識結帳系統的開發構想
要打造出一個簡易的菜色自動辨識結帳系統,我們主要需要克服如何辨識出顧客打了哪幾道菜。
我們有考慮過傳統CV與數位影像處理的方法,但因為每次的餐盤位置、菜色的擺放角度及當天的環境燈光顏色都不相同,真的硬走這條路會需要建一個相當複雜的模型。
相比起來機器學習的優勢正是利用通用的模型架構,透過大量資料的訓練,表達複雜模型處理的結果,對於我們的scenario是個比較容易的解決方案。
因此在這個專題中,我們會選擇一款機器學習的物件偵測模型,訓練模型能夠識別出餐盤中的各式菜色。當模型能夠識別出所盛的菜色後,接著只要累加所有預存在系統中各式菜色的金額即可得到顧客最終要付的錢了。除了計算結帳金額外,也可以加入像是計算卡路里等功能(後面會提到)。
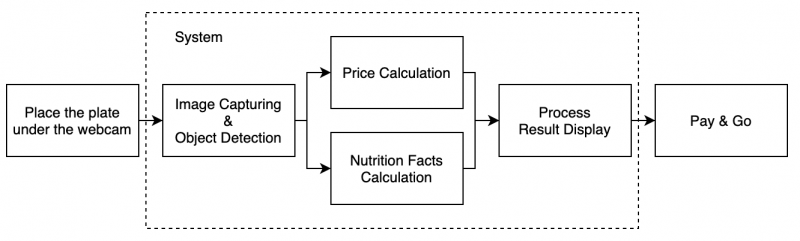
(自助餐菜色自動辨識結帳系統的運作構想)
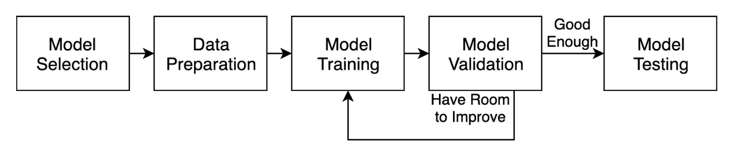
(機器學習模型的開發流程)
好啦前面講這麼多其實我一開始就是想在機器學習這個領域上練功啦:P
物件偵測的模型選擇(YOLOv3 vs Faster RCNN)
有了初步的構想,接著就先從最棘手的訓練辨識菜色模型克服起(因為做專題的時間不長,如果克服不了才有機會換題目XD)。我們一開始先做了些research,目標瞄準機器學習深度學習領域中的物件偵測模型,最後有納入考慮的有YOLOv3及Faster RCNN。先來說說Faster RCNN吧。
Faster RCNN
物件偵測模型Faster RCNN的運作方式分為兩個階段。第一個階段是模型會預測圖片中可能是物件的地方並產生候選框(region proposal),接下來將這些候選框交由分類器決定這個候選框到底屬於哪個種類。
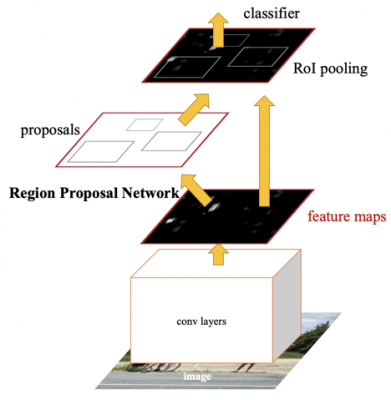
(Faster RCNN模型示意圖)
也因為這個模型有兩個階段,所以如果要在沒那麼高端顯卡的機器上跑real-time inferencing的話,fps不會太高。因此Faster RCNN先擺旁邊,我們來看看YOLOv3這個模型吧。
YOLOv3
YOLOv3改良了Faster RCNN需要兩步才能完成物件偵測的缺點,它只需要一步即可預測框及種類。它的偵測原理是先將同一張圖片切成13x13、26x26、52x52三種不同尺寸(圖左),然後分別在這切出來的格子中做辨識。每個格子中YOLOv3都會預測出三個bounding box(候選框)+bounding box的預測種類+bounding box預測種類的信心(圖中)。到這邊模型的預測已經結束了,剩下只要將信心太低的bounding box丟掉、重疊太頻繁的bounding box也捨棄掉,留下少數信心極高的bounding box即為最終的物件偵測結果(圖右)。

(YOLOv3模型示意圖)
由於我們希望這個自助餐辨識系統最終是可以安裝在結帳櫃臺上,做到real-time辨識菜色及協助計算價錢的,因此YOLOv3相比Faster RCNN只需花一步即可預測出框及種類成為了我們最終選擇它的主要原因。(我們希望餐盤一放到攝影機下螢幕上就計算好顯示出價錢了,不能lag太久)
訓練資料
決定好使用YOLOv3後,下一步就是要收集模型訓練用的資料。YOLOv3模型的輸入是全彩照片,輸出則是模型所預測的bounding box位置、預測種類、預測種類的信心。因此我們的訓練資料會是打完菜後餐盤的全彩照片+每樣菜色在照片中的正確座標。
自助餐每天都會有十幾種不同的菜色,而且有些菜色是季節限定不是每天都會供應。基於專題時間的緣故,我們將菜色縮小至12個幾乎每天都會出現的種類,分別是:白飯、紅蘿蔔炒蛋、咖哩、豆芽菜、雞塊、咔啦雞排、高麗菜、小煎餃、三角薯餅、香腸、煎荷包蛋、空心菜。並且在接下來的日子中我們幾個人就開始每天瘋狂地吃自助餐那12道菜,拍下收集打完菜後餐盤的照片供模型使用。整個專題做下來我們總共收集了575張餐盤照。
(收集的575張餐盤照)
有了那575張餐盤的照片,接下來就來到最累人的步驟了:將照片中每樣出現的菜色的正確座標框出來。有照片+正確的菜色的座標才能進一步引導模型學習那些座標上的各個種菜色的樣子。
在這邊我們使用了labelImg這個小工具協助框出菜色的座標,每框完一張餐盤照以後labelImg就會為每張照片中的座標資訊存一次檔。

(在labelImg中手動標記每樣菜色)
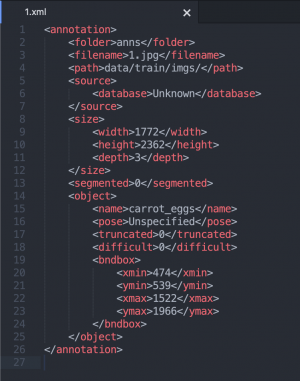
(每張餐盤照都會對應一個xml的座標存檔)

(575個餐盤照對應的xml座標存檔)
資料搜集加標記是整個專題花最多時間的一個環節。在專題剛開始初時我們想先用十幾張照片先訓練出一個模型的prototype來看看效果,結果因為資料量少,模型完全沒辦法generalize每樣菜的特徵。為此我們還以為程式有哪邊寫錯,狂對著程式debug也沒有頭緒。後來資料量漸漸多了,模型也慢慢開始抓到每樣菜色的特徵了。
在進入訓練模型之前,我們會希望將資料分成三堆,分別是訓練集、驗證集與測試集。訓練集的資料會被模型拿去直接訓練學習;驗證集的資料是當模型訓練完一輪訓練集的資料後拿來評估模型學習的成效用;當以驗證集評估模型學得差不多後,再用最後一堆測試集的資料對模型做盲測用。
為什麼要多此一舉將訓練集以外剩下的資料拆成驗證集與測試集兩堆呢?一組訓練集一組測試集不就好了嗎?我一開始也有這樣的疑問。後來教授跟我們說因為我們是看著模型對驗證集的評估結果來決定何時停止訓練,因此這也算"間接"洩漏驗證集的資料給模型。必需還有另一組資料是模型對它完全未知的,這樣最後測試準確率時才公正。這解釋確實有說服到我。
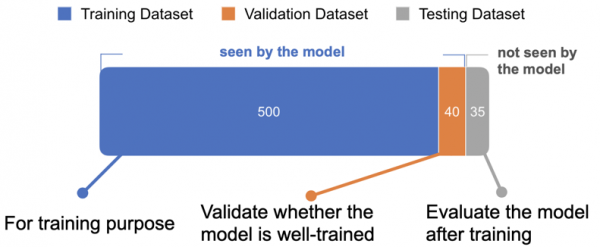
(575筆資料被拆成訓練集500筆、驗證集40筆、測試集35筆)
訓練模型
接著就把訓練集的那500筆資料丟去訓練啦。我們不直接指定訓練的次數,反之我們是設定early stopping的機制,當模型的損失連續5個epoch不再降低即停止訓練。換句話說就是模型的學習已經飽和了,無法再透過更多的學習次數讓損失降更低,此時我們就得到了相對最佳解的模型。
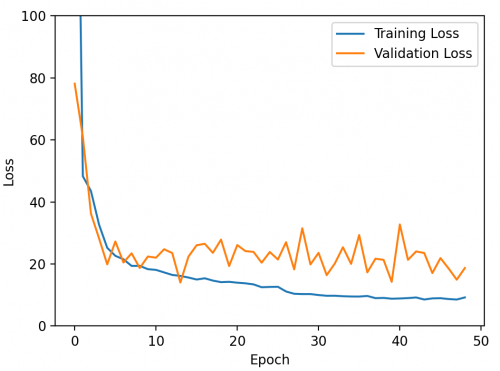
(訓練過程中的損失圖)
我們可以看到,在訓練過程的損失圖中大約第48次訓練時training loss及validation loss兩個同時微微往上翹不再下降了,因此整個訓練宣告終止。此趟訓練在Google Colab上使用Tesla P100的GPU執行了快6小時。
測試模型
當訓練完成後,我們就可以拿最後一次的模型存檔來在測試資料集上測測準確率。測試集是我們刻意保留的一份模型從未接觸過的餐盤影像,因此拿它來評估模型的準確率還算客觀。

(模型預測出菜色的位置及種類)
先隨便挑一張測試集的照片來試試模型表現得如何吧。我們看到模型對還是可以很有信心地從從未見過的照片裡辨識出炸雞排、空心菜、豆芽菜,但薯餅卻沒被偵測出來。
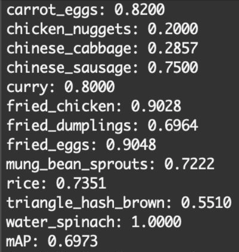
(在整個測試集上評估模型準確率)
除了手動跑一張張餐盤照片看結果,我們也可以拿一整個測試集下去評估準確率。可以看到模型對於所有種類的菜色的平均準確率(mAP)約70%。有些菜色像是雞塊(chicken_nuggets)的準確率特低只有20%,我們猜是因為訓練的資料量不夠(整個訓練集只有出現74次雞塊),相比空心菜(water_spinach)在整個訓練集出現了154次,準確率來到100%。我們相信專題如果有更多時間可以蒐集更多資料,整體的mAP可以拉到更高。
自動計算所盛菜色的結帳金額
機器學習做菜色偵測的部份到這邊就告一段落了,接下來要解決如何從已辨識出餐盤中的菜色計算結帳金額。我們這邊假設打菜還是由自助餐阿姨負責,所以可以撇除菜多菜少的問題。以及每位同學不會一次點兩份同樣的菜色,只要出現在餐盤上的菜色都以一份來計價為前提下去計算結帳金額。如此一來我們的程式只要將模型偵測出的菜色的金額全部加總就可以得到最後的結帳金額了。
以下是我們詢問自助餐阿姨那12道菜各自一份的價格:
- 白飯 10元
- 紅蘿蔔炒蛋 10元
- 咖哩 10元
- 豆芽菜 10元
- 雞塊 15元
- 咔啦雞排 30元
- 高麗菜 10元
- 小煎餃 15元
- 三角薯餅 15元
- 香腸 10元
- 煎荷包蛋 10元
- 空心菜 10元

(將明細及金額顯示在模型輸出結果的右半邊)
額外的附加功能:自動計算所盛菜色的卡路里
既然都能計算出價錢了,何不連營養資訊也一起標示呢?就好像去手搖飲店買飲料時,杯子上都會標示該杯飲料熱量多少大卡一樣的概念。為了專題,我們曾有段中午吃飯時間還帶著秤去學餐吃飯,然後點完自助餐餐盤後將每道菜放到秤上面秤重量。阿姨打菜的份量打得很精準,一道菜誤差不會超過±10%。給那12道菜測量個幾次後就以那道菜的平均重量去計算營養資訊。

(阿姨打的一份高麗菜約70g)
有了12道菜的重量後,下一步我們打開食譜app挑選出看起來吃起來長得跟自助餐阿姨煮得最像的食譜,看看人家每單位含了多少卡路里。

(高麗菜每100g所含的營養資訊)
然後將食譜中每單位的卡路里與阿姨打得菜色的平均重量做換算後寫進我們的自動辨識結帳系統裡。
成品
到這邊專題差不多就大功告成啦。左邊為攝影機的即時影像搭配YOLOv3模型辨識出的菜色,右邊為金額明細及卡路里明細。

(最終自助餐菜色自動辨識結帳系統的截圖)
看圖片可能沒那麼有震撼力,來一個real-time版的辨識結帳系統截圖給大家瞧瞧。
(自助餐菜色自動辨識結帳系統real-time版)
機器學習是不是真的很厲害,影片中不管以各種角度擺放餐盤,模型總有辦法辨識出菜色呢。以後自助餐阿姨可以放心地雇用一個工讀生負責結帳啦。(撒花~)
最後我也放上我們在專題口試日當天上台的presentation影片。
總結
本篇是我將大四專題從無到有的過程記錄下來寫成的網誌,希望可以給即將為大四專題煩惱的學弟妹們一個參考的案例。或者是正在閱讀本篇也對機器學習及電腦視覺領域有興趣的網友們參考一個小專案是如何從0開始到產出prototype的。
我在文章中也刻意都不提到任何程式碼是因為我覺得分享做每一步背後的動機比起直接放上程式碼更重要。用紀錄的方式走一遍機器學習的開發流程對以後再開發新的專案會比較有幫助,知道這一步該怎麼下手以及下一步應該做什麼。本篇的尾聲如果對程式碼部份感興趣的,也歡迎到我的Github下載整個專案:)
Andy您好,想請問您是如何製作測量準確率愈mAP的程式呢?我看了您的Github但有點不太懂
我是把執行每個epoch輸出的loss都寫log檔
之後再去parse log檔裡面的數值後用matplotlib產圖的唷
我畢業於野雞大學,一樣也是2020年,當年畢業專題跟你們做的一模一樣,我印像中評審還瘋狂批評說湯類的食物、混成洨的廚餘要怎樣處理
請問可否邀請您擔任講師分享相關議題,如何與您聯繫? 謝謝