最近在公司支援另一個採用PostgreSQL當資料庫的專案,雖然從語句面或使用ORM來看的話差異與熟悉的MySQL不大,但是當從併發的角度來看待效能時,才發現其實底層實現鎖的機制大不相同。本篇,我們會拿一個在實際專案中發生的簡化版情境,來介紹MySQL與PostgreSQL併發時底層實現鎖的運作過程。
目錄
- 準備資料
- 在不同資料庫執行相同語句
- 併發情況下MySQL的鎖機制
- 併發情況下PostgreSQL的鎖機制
- 結論
準備資料
這次我們實驗中會用到的資料庫版本是MySQL 8.0與PostgreSQL 14,分別在兩個資料庫中執行以下語句將資料建立起來。
MySQL 8.0
CREATE TABLE `order_record` (
`order_id` VARCHAR(36) NOT NULL,
`account_id` VARCHAR(32) NOT NULL,
`order_money` INT NOT NULL,
`status` INT NOT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`order_id`),
KEY `order_record_idx1` (`account_id`)
) ENGINE=InnoDB;
INSERT INTO `order_record`
(`order_id`, `account_id`, `order_money`, `status`, `create_time`)
VALUES
('976d40af-e4ad-4654-99a7-cbe1772e1771', '4189019448', 300, 1, '2022-07-29 07:18:20'),
('976d40b7-d9b9-4123-9ef1-3e153fda352d', '4423628756', 1000, 0, '2022-09-05 11:21:04'),
('976d40bc-20d7-4788-9e0b-a01e51628183', '4423628756', 1000, 0, '2022-09-05 11:21:04'),
('976d40c0-f3b7-4909-84d0-76c71151e0f2', '4420236455', 40, 0, '2022-09-08 21:19:07'),
('976d40c5-8c70-4303-8653-ac7775ce565f', '4420236455', 799, 0, '2022-09-09 06:39:30'),
('976d40ca-87e0-4a92-998f-cc6e681cb247', '4420236455', 701, 0, '2022-09-09 11:17:02');
PostgreSQL 14
CREATE TABLE order_record (
order_id uuid NOT NULL,
account_id varchar(32) NOT NULL,
order_money int4 NOT NULL,
status int4 NOT NULL,
create_time timestamp NOT NULL DEFAULT now(),
CONSTRAINT order_record_pk PRIMARY KEY (order_id)
);
CREATE INDEX order_record_idx1 ON order_record USING btree (account_id);
INSERT INTO order_record
(order_id, account_id, order_money, status, create_time)
VALUES
('976d40af-e4ad-4654-99a7-cbe1772e1771'::uuid, '4189019448', 300, 1, '2022-07-29 07:18:20.266'),
('976d40b7-d9b9-4123-9ef1-3e153fda352d'::uuid, '4423628756', 1000, 0, '2022-09-05 11:21:03.666'),
('976d40bc-20d7-4788-9e0b-a01e51628183'::uuid, '4423628756', 1000, 0, '2022-09-05 11:21:04.391'),
('976d40c0-f3b7-4909-84d0-76c71151e0f2'::uuid, '4420236455', 40, 0, '2022-09-08 21:19:07.075'),
('976d40c5-8c70-4303-8653-ac7775ce565f'::uuid, '4420236455', 799, 0, '2022-09-09 06:39:29.638'),
('976d40ca-87e0-4a92-998f-cc6e681cb247'::uuid, '4420236455', 701, 0, '2022-09-09 11:17:01.958');
在不同資料庫執行相同語句
當假資料建立完成後,接下來進入到我們實驗的情境吧。
某天,有一條連線1想要將所有account_id = '4423628756'的status欄位從0修改成1。在執行UPDATE前,連線1使用SELECT ... FOR UPDATE語句將要更新的資料取出並且上鎖,這樣在app層處理資料的同時可以避免其他人改動到資料,等app層處理完資料後再執行更新。此時,另一條連線2想要新增一筆同樣是account_id = '4423628756'的資料。我們來看看在不同資料庫下會發生什麼事吧。
MySQL 8.0
| Conn 1 | Conn 2 (general auto-commit mode) |
|---|---|
| SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; | |
| BEGIN; | |
| SELECT * FROM order_record WHERE account_id = '4423628756' FOR UPDATE; > 2 row(s) fetched. |
|
| INSERT INTO order_record (order_id, account_id, order_money, status) VALUES ('976d47fc-94e4-494b-a863-8c9bf1d4e7cc', '4423628756', 1000, 0); > (blocking...) |
|
| UPDATE order_record SET status = 1 WHERE account_id = '4423628756' AND status = 0; > 2 row(s) modified. |
> (still blocking...) |
| SELECT * FROM order_record WHERE account_id = '4423628756' FOR UPDATE; > 2 row(s) fetched. |
> (still another blocking...) |
| COMMIT; | > 1 row(s) modified. |
可以看到MySQL阻塞了連線2插入新資料的操作直到連線1 commit為止。等等我們會回來解釋為什麼會發生這個現象,我們暫時先切換到Postgres跑跑看相同情境的語句吧。
PostgreSQL 14
| Conn 1 | Conn 2 (general auto-commit mode) |
|---|---|
| BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ; | |
| SELECT * FROM order_record WHERE account_id = '4423628756' FOR UPDATE; > 2 row(s) fetched. |
|
| INSERT INTO order_record (order_id, account_id, order_money, status) VALUES ('976d47fc-94e4-494b-a863-8c9bf1d4e7cc', '4423628756', 1000, 0); > 1 row(s) modified. |
|
| UPDATE order_record SET status = 1 WHERE account_id = '4423628756' AND status = 0; > 2 row(s) modified. |
|
| SELECT * FROM order_record WHERE account_id = '4423628756' FOR UPDATE; > 2 row(s) fetched. |
|
| COMMIT; |
傑克,真是太神奇了。在Postgres環境下,連線2插入新資料的操作竟然沒有被阻塞。雖然MySQL跟Postgres最後都返回相同的結果,但是論在此情境下併發處理的能力,Postgres基本上略勝一籌。
接下來,我們來觀察一下MySQL跟Postgres底層是怎麼處理併發與鎖的機制,推敲出剛剛的情境會不會阻塞是怎麼決定的。
併發情況下MySQL的鎖機制
當我們在MySQL的交易查詢語句中加入了FOR UPDATE語法時,MySQL實際上是對索引order_record_idx1的account_id = '4423628756'條件加上了next-key lock,而next-key lock鎖的範圍是記錄本身+區間。因此,當連線1執行完查詢語句後就將整個account_id = '4423628756'區間都上鎖了,此刻,若連線2想要新增一筆同樣是account_id = '4423628756'的資料就會被阻塞一直到連線1完成或退回交易為止。
我們來驗證上面這段話看看。首先,開啟一個新的交易,並使用剛剛的查詢語句查詢+鎖定記錄。接著從系統表performance_schema.data_locks查詢當前獲得鎖的狀況。
| Conn 1 |
|---|
| SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
| BEGIN; |
| SELECT * FROM order_record WHERE account_id = '4423628756' FOR UPDATE; > 2 row(s) fetched. |
| SELECT INDEX_NAME, LOCK_TYPE, LOCK_MODE, LOCK_DATA FROM performance_schema.data_locks; |
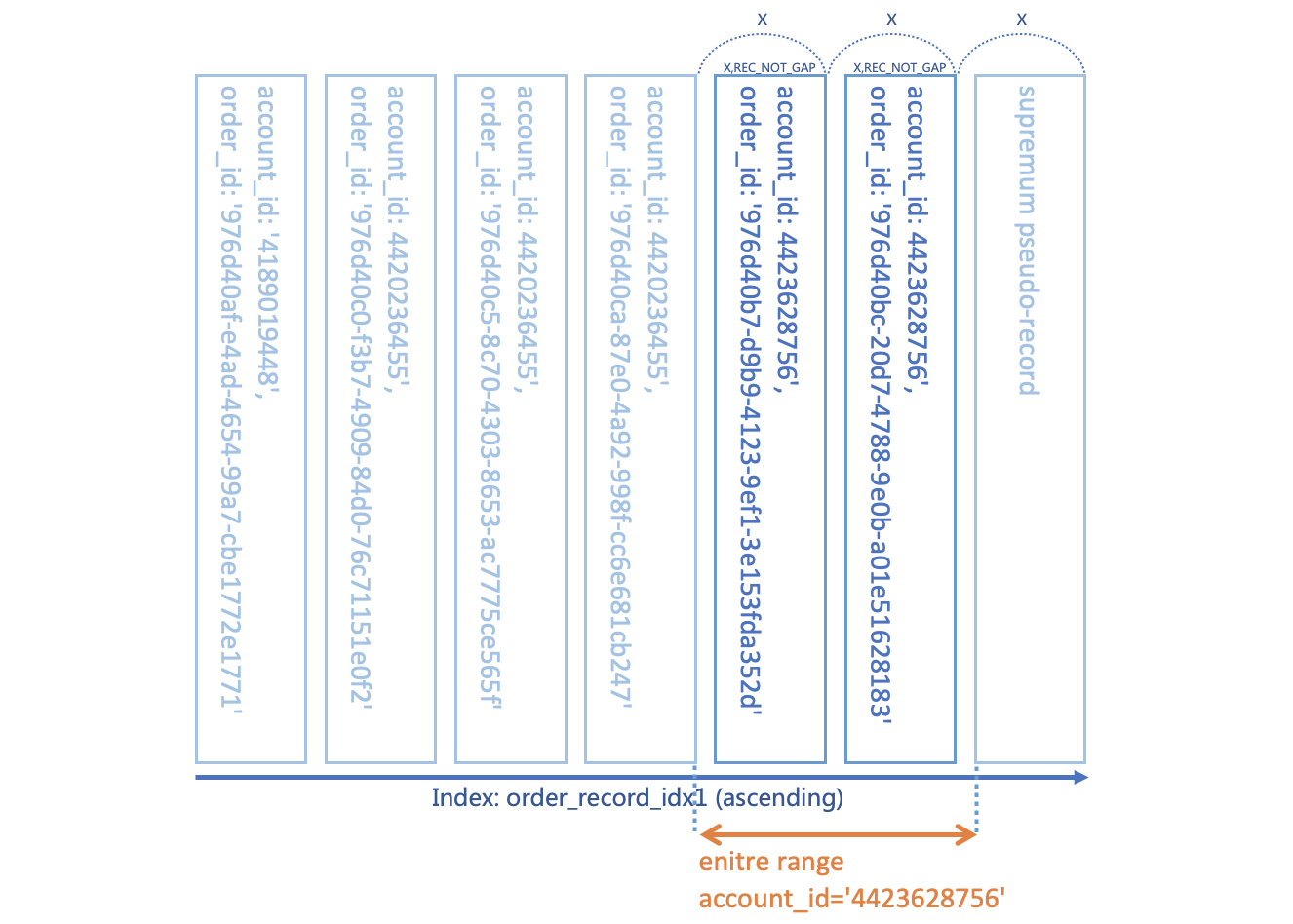
INDEX_NAME |LOCK_TYPE|LOCK_MODE |LOCK_DATA |
-----------------+---------+-------------+----------------------------------------------------+
|TABLE |IX | |
order_record_idx1|RECORD |X |supremum pseudo-record |
order_record_idx1|RECORD |X |'4423628756', '976d40b7-d9b9-4123-9ef1-3e153fda352d'|
order_record_idx1|RECORD |X |'4423628756', '976d40bc-20d7-4788-9e0b-a01e51628183'|
PRIMARY |RECORD |X,REC_NOT_GAP|'976d40b7-d9b9-4123-9ef1-3e153fda352d' |
PRIMARY |RECORD |X,REC_NOT_GAP|'976d40bc-20d7-4788-9e0b-a01e51628183' |
以下是上鎖結果對應到記錄的示意圖。當我們要對表中的記錄上鎖前,MySQL首先會先對這張表放置排他意象鎖鎖(IX),這種鎖的用意是告訴其他連線目前有人打算/正在對此表中的某些記錄加鎖,如果其他人要上全表鎖請等待。接下來,我們看到兩個X,REC_NOT_GAP種類的鎖,這兩個鎖正是鎖在記錄上的排他鎖。最後剩下的三個,X種類的鎖是我們前面提到的next-key lock,next-key lock會鎖定此記錄本身以及記錄前面的區間。從示意圖中我們可以看到這五個有實際作用的鎖所構成的鎖定範圍,將整個account_id = '4423628756'都保護好讓不是上鎖人無法異動了,可謂解鈴還須繫鈴人。
鎖的種類:
IX: 排他意象鎖
X: Next-Key Lock
X,REC_NOT_GAP: 排他鎖
理解了MySQL上鎖的過程了,我們來想想看為什麼MySQL要上next-key lock將整個區間都給鎖定呢?如果只鎖剛好記錄本身會發生什麼事情呢?這就要講回到MySQL隔離層級的可重複讀(repeatable-read)了。隔離層級的可重複讀規範了在同個交易中,每次查詢所看到的記錄都必需一致,不能讀到別人異動不管是commit或沒commit的記錄。因此,如果MySQL今天鎖定的只有單純記錄本身而不是區間,那連線2所插入同為account_id = '4423628756'的記錄將會被連線1所看見,嚴重違反可重複讀的定義。也就是這個原因,我們可以了解為什麼MySQL加鎖的範圍是區間而不是單單記錄本身了。
下一段,我們來看看Postgres是怎麼實現在只鎖定記錄本身的前提下,允許其他連線插入資料進區間,但是卻又達到可重複讀的標準
併發情況下PostgreSQL的鎖機制
Postgres在底層儲存的資料結構上就與MySQL完全不同,而且也沒有間距鎖或next-key lock的概念。在儲存每條記錄時,Postgres將每條記錄都視為唯讀記錄(imutable tuple)。因此,在Postgres的世界裡,修改記錄等於把原先的記錄標記刪除(不用擔心會有背景程式自動回收),再同時新增一筆新的修改好的記錄至同張表內。同時,為了區別每條唯讀記錄,Postgres也會為每條記錄新增一個叫ctid的隱藏欄位,代表該記錄在此表中的實體位址。也就是說,當我們修改一次Postgres資料表中的資料,資料的ctid欄位也會跟著更新,因為更新的資料即一條新的唯讀記錄。除此之外,Postgres還有加入了另一個叫xmin的隱藏欄位,他的值是由插入此記錄的交易ID決定。
有了這兩個最基本的設計,我們等等就可以來看Postgres是怎麼實現不鎖區間的可重複讀的。在此之前,我們先熟悉一下ctid及xmin實際的運作方式。
| Conn 1 | Conn 2 |
|---|---|
| BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ; | |
| SELECT TXID_CURRENT();
> 1071 |
|
| SELECT ctid, xmin, * FROM order_record WHERE account_id = '4423628756' FOR UPDATE; |
ctid |xmin|order_id |account_id|order_money|status|create_time | -----+----+------------------------------------+----------+-----------+------+-----------------------+ (0,2)|1049|976d40b7-d9b9-4123-9ef1-3e153fda352d|4423628756| 1000| 0|2022-09-05 11:21:03.666| (0,3)|1049|976d40bc-20d7-4788-9e0b-a01e51628183|4423628756| 1000| 0|2022-09-05 11:21:04.391|
上面第二句的SELECT TXID_CURRENT();查詢的是當前連線1開啟的交易ID,目前是1071。第三句我們撈出剛剛新介紹的ctid跟xmin隱藏欄位,可以看到目前查詢的記錄在此表中的第2跟3的位址上,並且當時是由ID為1049的交易插入的。在Postgres的世界裡,FOR UPDATE語法不像MySQL那樣會去鎖除了記錄以外的東西,他很單純地就真的只鎖了上面的那兩條記錄。
現在,我們打開另一個視窗開啟連線2並且插入及返回新的記錄包含ctid跟xmin看看。
| Conn 1 | Conn 2 |
|---|---|
| BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ; | |
| SELECT TXID_CURRENT();
> 1072 |
|
| INSERT INTO order_record (order_id, account_id, order_money, status) VALUES ('976d47fc-94e4-494b-a863-8c9bf1d4e7cc', '4423628756', 1000, 0) RETURNING ctid, xmin, *; |
ctid |xmin|order_id |account_id|order_money|status|create_time | -----+----+------------------------------------+----------+-----------+------+-----------------------+ (0,7)|1072|976d47fc-94e4-494b-a863-8c9bf1d4e7cc|4423628756| 1000| 0|2022-9-11 01:26:42.219|
這次,我們取得的交易ID是1072,比連線1的交易ID多1,並且也可以看到此筆記錄的xmin正是此交易ID,與剛剛的說法吻合。此外,我們也可以看到這筆新記錄寫入在此表中的第7的位址上。
講到這裡,我們終於可以來解說Postgres實現可重複讀的秘密了。連線1為了實現可重複讀,在撈取記錄時會自動略過大於自己交易ID(1071)的xmin的記錄。為什麼呢,我們可以換個角度想,當記錄的xmin大於自己的交易ID時,代表這些異動(不管是因為修改而新增或者真的是新的一筆記錄)是在當前交易開始後才寫入的,所以為了實現可重複讀,連線1只需讀取xmin小於等於交易ID的記錄即可,如此就可以確保記錄都是合法有效的。是不是有種豁然開郎什麼都串起來的感覺呢。
為了驗證這個說法,我們回到連線1並將所有符合account_id = '4423628756'條件的記錄更新status從0到1,看看那些記錄被更新了。
| Conn 1 | Conn 2 |
|---|---|
| UPDATE order_record SET status = 1 WHERE account_id = '4423628756' AND status = 0; RETURNING ctid, xmin, *; |
ctid |xmin|order_id |account_id|order_money|status|create_time | -----+----+------------------------------------+----------+-----------+------+-----------------------+ (0,8)|1071|976d40b7-d9b9-4123-9ef1-3e153fda352d|4423628756| 1000| 1|2022-09-05 11:21:03.666| (0,9)|1071|976d40bc-20d7-4788-9e0b-a01e51628183|4423628756| 1000| 1|2022-09-05 11:21:04.391|
是不是,與前面的說法吻合呢。只有原先撈出xmin = 1049的那兩條記錄被更新了,而且也可以看到ctid顯示新的唯讀記錄是插入在表中的第8跟9的位址上,並且xmin也換成了目前連線1的交易ID1071,完整示意圖如下。
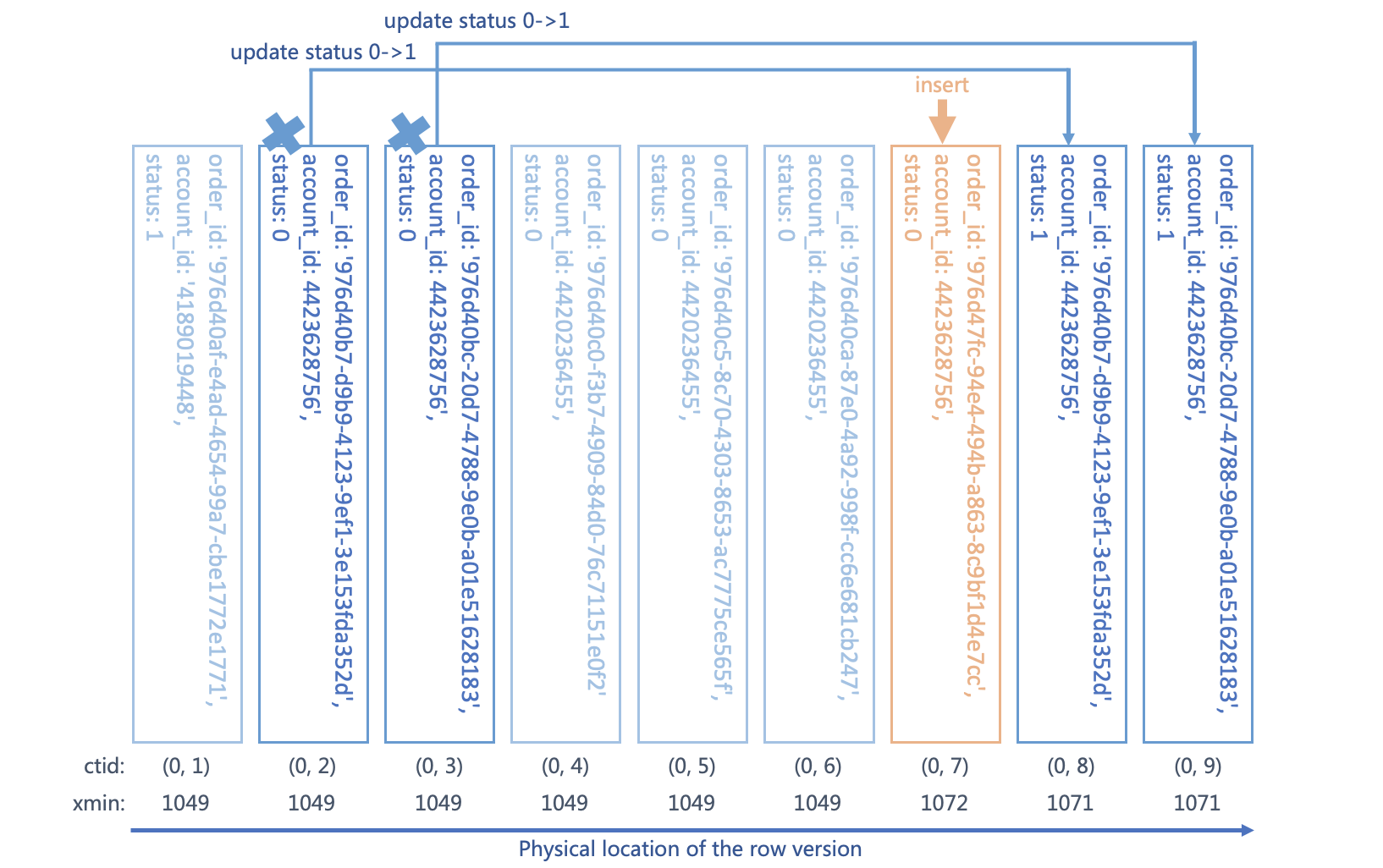
到目前為止,我們已經完整走完一遍Postgres底層是怎麼藉由他先天設計上的優勢,實現不用像MySQL一樣上next-key lock將整個區間都給鎖定就可以達成可重複讀了。
結論
由於MySQL與Postgres在先天底層儲存資料結構設計上的差異,造就在併發情況下有著全然不同的鎖機制存在。我也是因為這次有幸支援到另一個採用Postgres當資料庫的專案,為了debug效能上的問題,才有機會深入理解這兩種資料庫底層是如何運作的。藉此,想記錄一下使用完這兩種資料庫的心得。
最後的最後再補充一下,上面舉例的情境有關可重複讀(repeatable-read)的部分,其實是非常簡化的版本,目的只是想帶大家用最淺顯易懂的方式體驗一遍兩種資料庫的運作機制。並且,實作可重複讀的機制是有個專有名詞叫多版本併發控制MVCC (multi-version concurrency control)的,有興趣可以去資料庫的官網翻翻看,裡面會有文章說明更多哪些資料該被讀出哪些該視而不見。
至此本篇終,希望透過這篇文章能讓大家更了解MySQL與PostgreSQL兩種資料庫,謝謝閱讀。
參考資料
- https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
- https://dev.mysql.com/doc/refman/5.6/en/information-schema-innodb-locks-table.html
- https://www.postgresql.org/docs/14/ddl-system-columns.html
- https://postgrespro.com/blog/pgsql/5967899
- https://dev.to/techschoolguru/understand-isolation-levels-read-phenomena-in-mysql-postgres-c2e#repeatable-read-isolation-level-in-mysql