公司的Node.js專案在經過好幾年的需求迭代後多少會出現些bad smells,為了解決這些bad smells於是又誕生了一些偏門的寫法,但卻也換來目前開發上很難確認眾多變數中哪些變數會是undefined(對,我們的專案已經寫到連eslint的一些rule都認不得了)。因此最近在研究如何為專案的eslint增加客製化的rule,補上讓eslint去抓出偏門寫法中的undefined變數。
在做了些研究後,發現eslint在為某個檔案做靜態檢查時,會先將整份檔案的程式碼讀一遍,並且建立抽象語法樹(Abstract Syntax Tree),然後透過遍歷這棵樹的操作去抓出沒有符合rule的地方。
其實不只是eslint,所有編譯器、直譯器在拿到一份程式碼時第一步也是先建立抽象語法樹,所以今天這篇要來簡單介紹什麼是抽象語法樹(Abstract Syntax Tree),或簡稱AST。
抽象語法樹是什麼
回想一下我們平常寫的程式碼,有類別、變數、函式,而函式裡面又可以宣告變數、條件式、函式,某種程度上看起來就是巢狀的形狀。
但是以電腦的角度來看,一份程式碼文字檔終究只是一個加入了大量換行符號及縮排的字串。所以編譯器、直譯器、linter如果要讀懂這份程式碼,需要將程式碼字串先轉換為某種電腦可以辨識的資料結構後才能做後續的應用。
對於看起來像巢狀形狀的程式碼,大家應該不難猜到用樹的資料結構來表示最為符合,所以這個由程式碼字串建構出來的的樹狀資料結構就叫抽象語法樹。
例如以下這段短短的js程式碼:
function sayHello(name) {
const greet = 'Hello ' + name;
return greet;
}
sayHello('Andy');
經過解析建構出來的抽象語法樹就會長這樣。
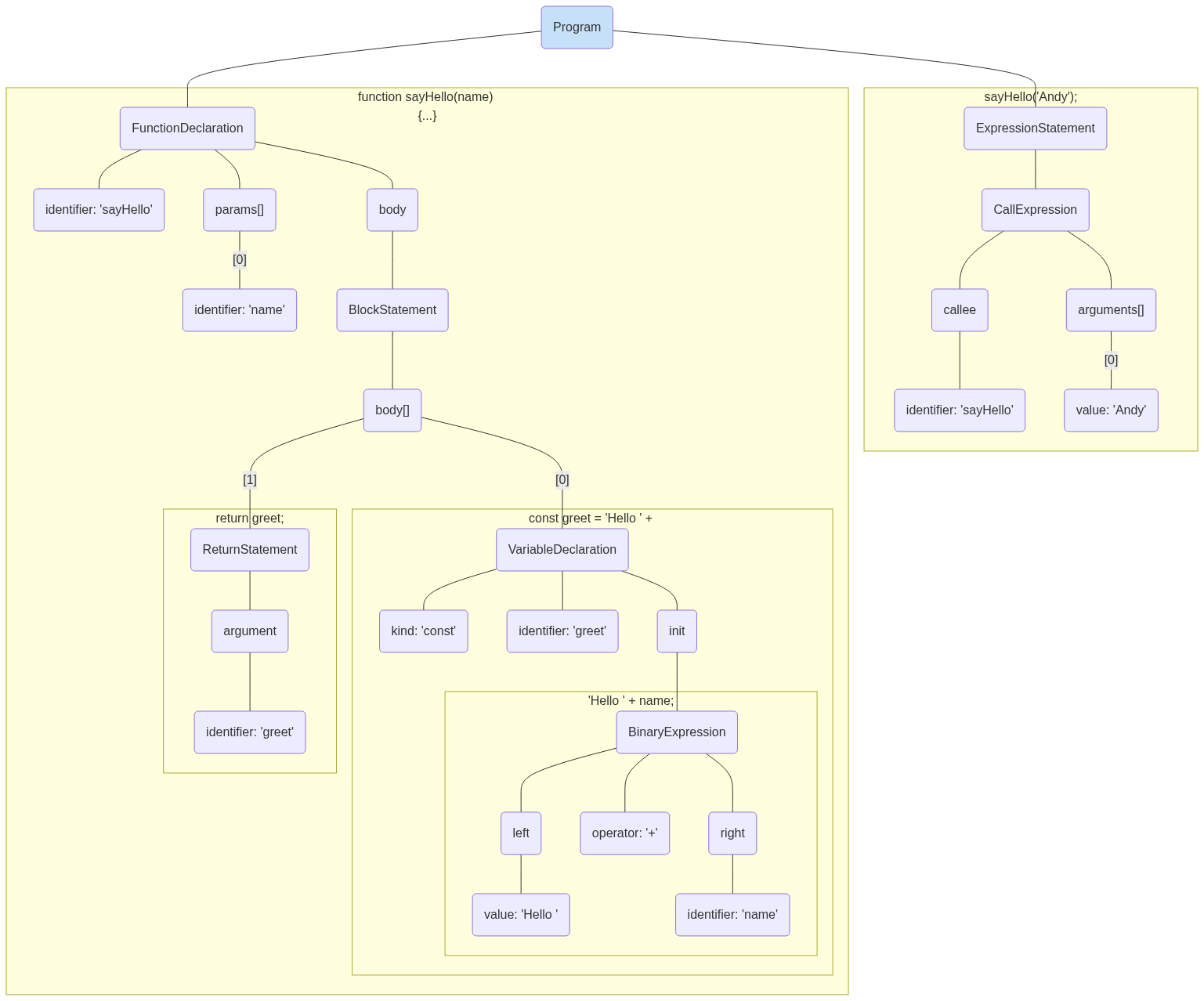
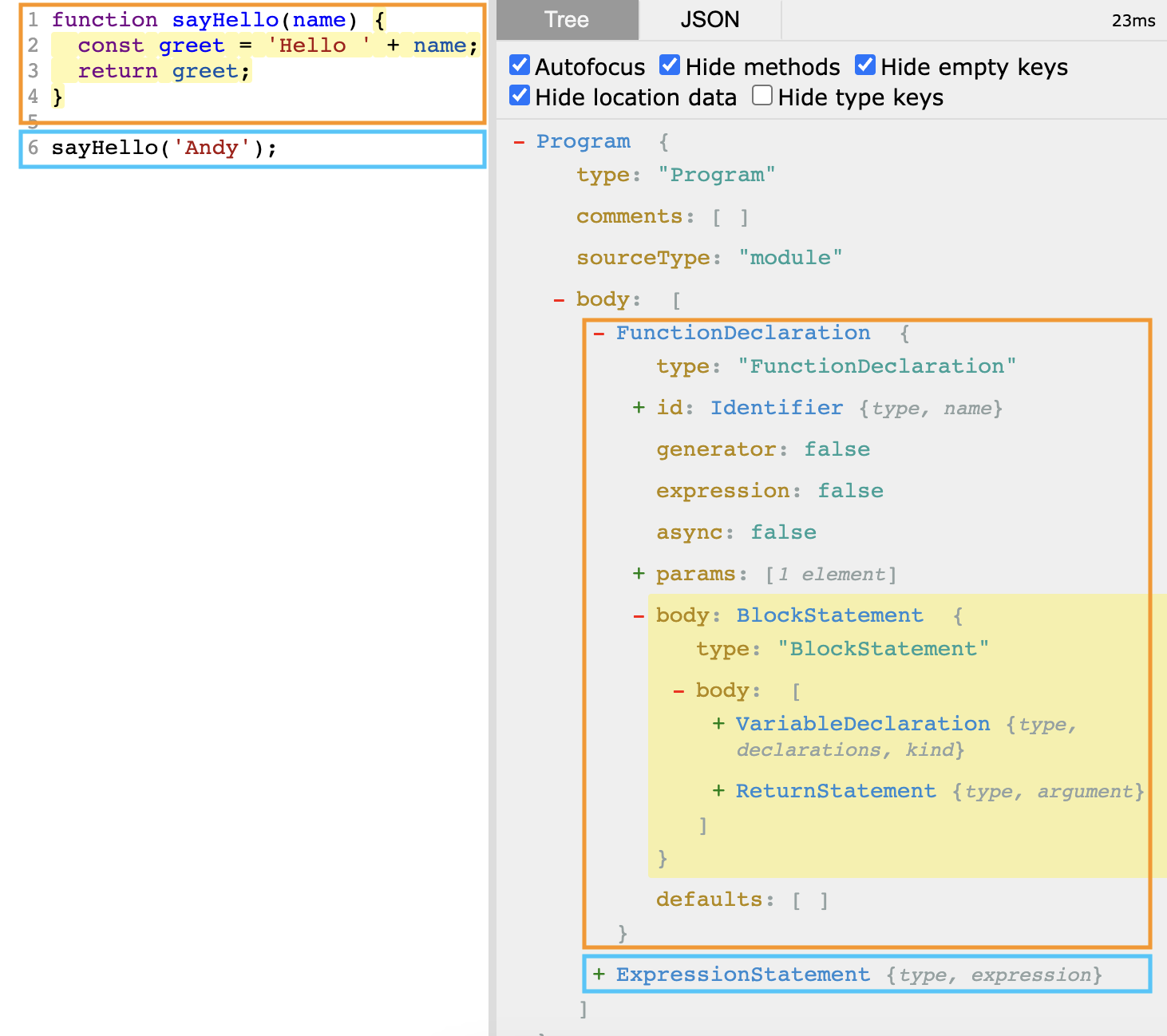
是不是頓時可以感受到爲什麼會選擇用樹來做解析後的資料結構了呢。除此之外,我們也可以用 https://astexplorer.net/ 這個網站提供很好的程式碼轉換成抽象語法樹的互動,把剛剛上面那6行程式碼餵進去,讓它幫我們轉換成抽象語法樹的json物件。
SQL也是如此,當今天SQL被送到DB後,第一步也是會先經過一層parser解析SQL語句成為抽象語法樹,接著才會送去query optimizer產出我們平常看到的query plan,最後才是將選中的plan拿去execute。
SELECT
ID,
NAME,
CREATE_TIME
FROM USER
WHERE ID = 3;

到處都可以看到抽象語法樹的影子呢。
抽象語法樹的應用
當程式碼從字串轉換為抽象語法樹後,除了最基本的編譯器、直譯器拿去打包成binary code或byte code執行外,基本上所有對於程式碼檔案解析的應用都是基於抽象語法樹往上延伸。
例如最一開始會認識抽象語法樹的動機就是想為eslint增加客製化的rule、或是VSCode如何做到將程式碼中的變數及函式等等不同種類的行為進行不同顏色的highlight及連結跳轉、又或JS生態系中的transpiler如何將新版語法降版替換為舊版語法兼容更多瀏覽器版本、甚至更誇張的例子將A語言翻譯為B語言(不考慮依賴的套件的話),這些都是基於抽象語法樹可以做到的應用。
結論
看到這邊,大家應該都已經了解電腦是如何從一份純文字檔的程式碼中讀懂裡面的每行語法了。在產生抽象語法樹後,剩下的應用基本上都圍繞著樹的遍歷。這也讓我領悟到為什麼computer science中這麼強調樹的資料結構,甚至大公司面試、leetcode刷題時都會有樹的存在。