當服務在面對用戶量逐漸增加並且效能逼近單台的server極限時,身為技術團隊就必須想辦法為服務進行水平擴展,將服務拆分並且佈署至多台機器上形成分散式系統。
在畢業後在業界打滾幾年後,深深覺得學習分散式系統不能再用實務上看到一個坑才填一個坑的方式學習,因為坑實在太多了,而且職場上沒有那麼多機會及容忍度可以一個坑一個坑慢慢踩慢慢填。
於是就在某天跑完天瓏書局後就把《分散式系統主流框架實作指南》這本書也一起帶回家了,本篇將分享讀完這本書後的每章筆記,如果對於筆記內容覺得不錯的歡迎支持閱讀原作。

目錄
第1章:概論
- 應用程式的演進歷程:單體架構->單體叢集->微服務。
- 分散式應用會遇到的問題:
- 一致性
- 節點發現
- 節點呼叫
- 節點協作
第2章:一致性
- ACID的一致性:交易前後均需滿足業務邏輯設定的constraint。
- CAP的一致性:當在某個節點上進行了變更操作,則在一定時間後,所有節點都可以讀到這個變更結果。
- 只有在分散式交易中,ACID的一致性才會與CAP的一致性重疊,不然平常很少有交集。
- 對話時要區分好兩種一致性,才不會雞同鴨講。
- 一致性的強弱:
- Eventual Consistency(最終一致性):CAP的AP採用的模型,只要在某個節點上進行了變更操作,只要能保證在一定時間後,所有節點都可以讀到這個變更結果即可。
- Sequential Consistency(順序一致性):單一節點的所有事件在全局事件歷史上符合程式的先後順序。且全局事件歷史在各節點一致。例如某個節點有delay的現象但是還是符合順序,則這樣也是合法的。
- Atomic Consistency、Linearizability(線性一致性):在sequential consistency(順序一致性)新增一個約束。如果事件B的開始時間晚於事件A的結束時間,則在全局事件歷史中,事件A在事件B之前。例如資料庫加鎖的併發,操作的範圍沒有overlap則允許併發,有的話則加鎖等待。
- Strict Consistentcy(嚴格一致性):序列化的,系統完成上一個動作才會去做下一個動作,性能極差,基本上不會應用在現實中。
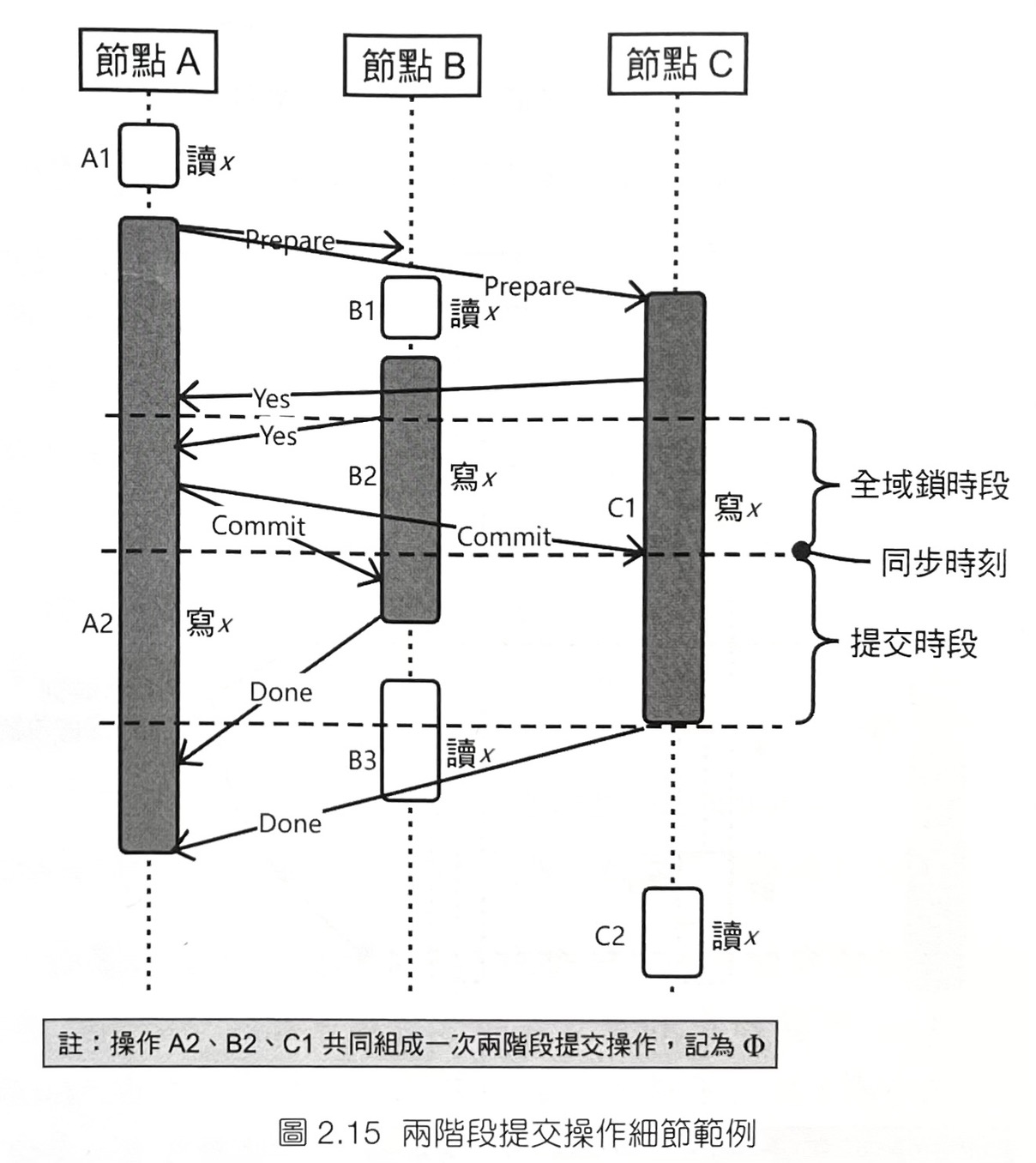
- 2 Phase Commit
- 協調者向參與者發送prepare訊息,其中訊息包含變更的內容。參與者收到訊息後將操作包裝成交易但還不提交,並回覆協調者yes。如果協調者收齊所有參與者的yes則發送commit訊息讓所有參與者提交先前的交易。如果一定時間內收不齊所有參與者的yes回覆,則發送rollback訊息讓所有參與者取消剛剛的交易。
- 缺點:
- 同步阻塞問題:參與者收到協調者發出的prepare訊息後,會開啟交易完成訊息中的操作。交易的開啟表示參與者的併發處理能力將受到很大的影響。而且,參與者不是一個節點而是一群節點,所以整個系統中的節點都會因為交易的開啟而阻塞。這個過程可能很長,要等待協調者收集完參與者的訊息並進一步發佈訊息後,該過程才能結束。
- 單點故障:2 phase commit高度依賴協調者發出的訊息,因此存在單點故障。如果協調者在兩階段提交的過程中出現問題,則會導致系統失控。尤其是在prepare開始後、commit前,如果此時協調者當機,則會導致己經開啟了交易的各個參與者既不能收到commit訊息,也收不到rollback訊息。這樣交易會無法結束,從而造成系統全域阻塞。
- 3 Phase Commit
- 協調者向參與者發送can commit訊息,參與者此時需回覆yes/no決定是否能參與交易,如果一定時間內有參與者回覆no則協調者需發送abort訊息給所有參與者。當所有參與者都回覆yes後下一步就會進入pre commit階段。此階段協調者向參與者發送pre commit訊息,其中訊息包含變更的內容。參與者收到訊息後將操作包裝成交易但還不提交,並回覆協調者ack。當協調者收齊所有參與者的ack後則發送commit訊息讓所有參與者提交先前的交易,反之則發送rollback訊息。
- 優點:
- 改善2 phase commit的阻塞問題。在3 phase commit的最後一個do commit步驟如果參與者在一定時間內沒有收到commit訊息預設timeout後還是會commit,理由是既然已經進入do commit階段代表所有參與者在can commit都回應了yes,所以就假設了所有參與者都應該是可以提交的。這個好處是如果協調者當機不會造成整個系統阻塞。此外如果協調者在發出commit後當機,則整個系統的狀態也還是確定的,因為各個參與者都會預設提交交易。
- 缺點:
- 如果協調者在發送rollback訊息的過程中當機,一部分参與者收到rollback訊息回覆交易,另一部分參與者因為没有收到rollback訊息便會預設提交交易。將會導致系統的一致性被打破,而且即使選列出新的協調者,也無法判斷哪些參與者回覆了交易,哪些參與者提交了交易。
- 一致性證明
- 在全域鎖時段禁止讀取變更但未提交的操作,如果有重疊的操作必須阻塞。由於這個約束可以保證n phase commit滿足了atomic consistency(線性一致性)。換句話說,不存在併發請求導致讀取到不同的值。
- 驗證:在全域鎖時段前的所有已處理的讀取請求都將返回x的舊值,如果某節點已經進入prepare階段則阻塞直到交易結束;在同步時刻後的讀取請求都將返回x的新值。由此可說n phase commit滿足了atomic consistency(線性一致性)。
第3章:共識
- 共識與一致性的區別
- 共識:一整個分散式系統中投票表決該選擇哪個訊息commit進歷史則為共識。例如班級出遊大家投票表決去哪玩。
- 一致性:任意節點對外發布的消息是一致的。例如隔壁班小明問我們班出遊去哪玩。
- 一致性有強弱之分,而共識沒有。例如隔壁班小明問我們班今天請假沒來的小華我們班班級出遊去哪玩,由於小華沒去學校還不知道討論結果,所以必須等隔天去學校後才能告訴小明(阻塞),此情境符合atomic consistency(線性一致性)。
- 拜占庭問題
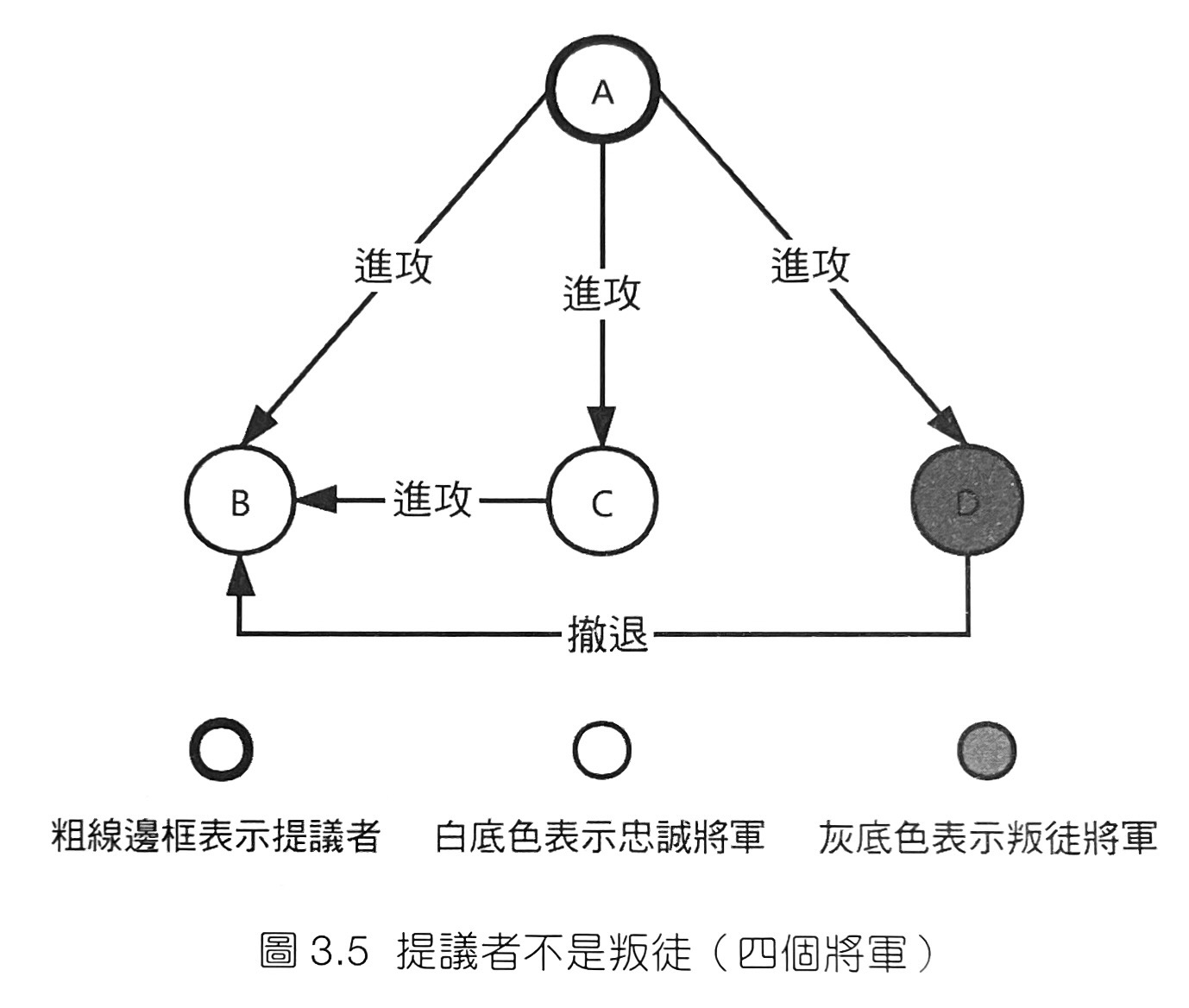
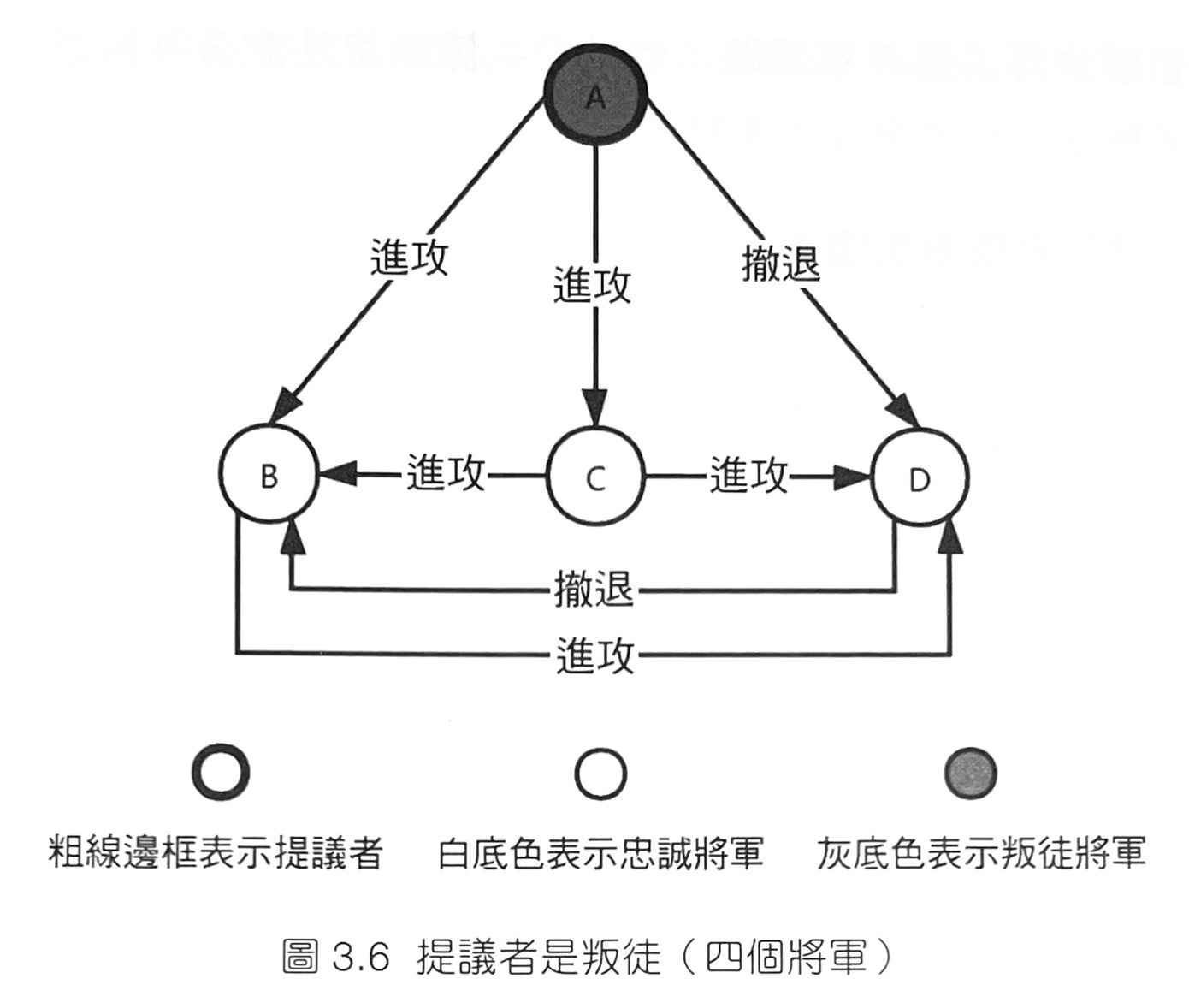
- 拜占庭軍隊圍困了一座敵方城池。整個拜占庭軍隊可以分為n部分,而每個部分均只聽命於對應的將軍。任意兩個將軍之間可以透過信使進行通訊。現在,軍隊的各個將軍必須要制定一個統一的行動計畫,即某個時刻進攻還是撤退。然而,在將軍中存在叛徒,他們會透過說謊等手段盡量阻撓忠誠的將軍達成共識。當叛徒將軍的數目t和將軍總數n滿足n≥3t+1時,忠誠的將軍還是可以達成共識。
- 書中舉例n=4,t=1:
- 拜占庭容錯演算法
- 基於非拜占庭容錯演算法之上,加入獎懲機制,將善意的節點權重提升,降低惡意節點的權重,主要應用在區塊鏈領域較多。
- 非拜占庭容錯演算法
- 允許分散式系統中存在故障節點,但是不能處理存在惡意節點的共識演算法。
- Paxos共識演算法
- Prepare階段:proposer選擇一個提案編號n放入prepare請求中發送給acceptor。如果acceptor收到的prepare請求編號n大於它已經回覆的所有的prepare請求的編號,則回覆proposer接受該prepare請求。在回覆proposer的請求中,acceptor會將自己之前收到的編號最大的提案(如果有的話)回覆給proposer。進行了這次回覆後,acceptor承諾不會再回覆任何編號小於n的提案請求。當proposer收到了多數acceptor對prepare請求的回覆後,進入accept階段。
- Accept階段:proposer向acceptor們發出accept請求。accept請求中包含編號n和決定出的value。這個value是它在prepare請求的回覆中收到的編號最大的提案中的value。如果不存在這個value,則該proposer可以自由指定一個value。acceptor收到這個accept請求後立刻接受,除非該acceptor又已經回覆了編號大於n的prepare請求。
- Raft共識演算法
- Leader選舉階段:每個節點啟動時都是follower模式,當愈時都一直沒有收到leader的hart beat代表與leader失去聯絡,此節點即進入candidate模式,開始新的leader選舉。如果當前節點獲得了多數節點的投票,則會進入Ieader模式做為叢集的leader。不然可能會收到新leader的資訊而退回 follower的模式,也可能會因為超過一定時間未收到新leader的資訊而繼續處於candidate模式,並進行下一輪的投票。
- 變更處理提案表決階段:由leader發布變更請求,當quorum的follower都接受請求處理後即為請求完成,類似DB的master-slave模式。
第4章:分散式約束
- CAP定理
- 在分散式系統中,無法擺脫一致性(C)、可用性(A)、分區容錯性(P)中進行三選二的抉擇,三個特性無法同時滿足。
- 一致性(C):指一致性中的atomic consistency(線性一致性)。關於這點,我們已經在第2章中進行了詊細的介紹,這裡不再贅述。
- 可用性(A):指分散式系統總能在一定時間內回應請求。舉例來說,向分散式系統發出某個變更請求,分散式系統會在一定時間內完成操作。
- 分區容錯性(P):指系統能夠容忍網路故障或部分節點故障,即在這些故障發生時,系統仍然能夠正常執行。
- 滿足CA:這就表示節點A和節點B之間的通訊必須永遠正常,任何資料變更操作都能立即在兩節點間同步,系統總能回應外部請求,且寫入系統中的資料可以被立即讀出。在這種情況下,便沒有通訊故障的分區容錯性的需求,於是系統可以保證一致性與可用性。
- 滿足AP:因為系統具有分區容錯性,所以我們假設節點A和節點B之間的通訊發生故障。如果使用者在節點A上發起了資料寫入請求,為了保證可用性,那麼節點A必須在無法將寫入請求同步到節點B的情況下處理資料寫入請求。但這會導致使用者無法從節點B中讀出更新後的資料,即寫入的資料無法被立即讀出,即系統無法再保證一致性。
- 滿足CP:同樣,我們假設節點A和節點B之間的通訊發生故障。如果使用者在節點A上發起了資料寫入請求,為了保證一致性,那麼節點A必須拒絕寫入資料,因為只要節點A在與節點B失聯的情況下寫入了資料,就表示一致性被打破。於是寫入請求無法被處理,即系統無法再保證可用性。
- 在CAP定理中證實了三者不能同時被滿足,但是不代表一定要三選二,我們希望可以放棄一點C換取一點A,滿足部分一致性、部分可用性,在兩者之間取得平衡。
- BASE定理
- 我們希望可以放棄CAP定理中的atomic consistency(線性一致性),轉而追求eventual consistency(最終一致性),以換求部分可用性,這就是BASE定理。
- BASE:Basically Available、Soft State、Eventual Consistency。
- Basically Available
- 功能裁剪:系統損失部分功能,保證另一部分功能可用。舉例來說,在競拍系統中,仍然可以進行商品的競拍,但是出價後不再顯示該使用者的所有出價記錄。
- 性能降低:系統仍然可用,但容量、併發數、回應時閒等性能指標降低。舉例來說,對競拍商品出價後,系統回應過程變長。
- 準確度降低:系統仍然可用,但列出的結果的準確度降低。舉例來說,對競拍商品出價後,不再顯示全域最高價的準確值而只是一個估計值。
- Soft State
- 在節點同步的過程中,有些節點可能還沒接收到狀態更新的訊息,所以a=3,而一些已經接收到節點更新的訊息的節點已經更新a=5。這個中間態則為soft state。
- Eventual Consistency
- 當所有節點都接收到更新的訊息並更新至a=5,則soft state又恢復至hard state,而任何人對任一節點查詢都會得到a=5,此為eventual consistency的結果。
- 假設分散式系統中的部分節點發生故障,則按照BASE定理,系統應該確保basically available,即繼續使用剩餘節點對外提供服務。如果某些功能依賴故障節點,則可以將這些功能裁剪掉。
- 當外界發來孌更請求時,系統應該進入soft state,即正常節點接收並應用孌更,而故障或失聯節點維持原有狀態不變。此時外果存取系統,可能讀到變更前的結果也可能讀到變更後的結果,這取決於存取請求具體落在了哪類節點上。
- 為了實現eventual consistency,當故障或失聯節點恢復後,應該及時從正常節點同步最新狀態。這需要滿足以下要求:
- 系統中的最新狀態必須是唯一確定的。由於系統狀態的改變是由更新觸發的,所以只要保證系統中的更新序列是唯一的即可。可以對系統中的每一項更新分配一個唯一旦遞增的編號,進而保證更新的有序性和唯一性,而最高編號的變更執行後的狀態即為系統最新狀態。
- 存在將任意節點的狀態同步到最新狀態的機制。可以要求某個節點在發現系統中存在較新的狀態後,自動將自身狀態與較新狀態之間的篓更序列補齊。
- 若發生split brain的情況,可以透過共識演算法的機制選擇多數決決定的結果apply至自身。
第5章:分散式鎖
- 分散式鎖要滿足三個特性:全域性、唯一性、遵從性。
- 全域性:必須在作用範圍內全域可見。
- 物理全域性:鎖存在一個全域可見的物理媒體上,例如單台redis。
- 一致全域性:鎖存在滿足atomic consistency(線性一致性)的分散式系統中,例如redis cluster,並採用redlock演算法。
- 邏輯全域性:沒有儲存鎖的物理媒體,反而以一個全域邏輯的形式儲存於每個節點中。例如星期一排程由節點1負責,邏輯上確保不會有concurrency發生。
- 唯一性:不允許同一功能在同一時間出現兩個鎖。
- 遵從性:不允許同一功能有部分節點繞過鎖展開操作,各節點必須遵從分散式鎖。
- 全域性:必須在作用範圍內全域可見。
- 分散式鎖的設計要點:高可用、讀寫快、自解鎖。
- 分散式鎖的實作種類:
- 邏輯分散式鎖:例如有7個節點,則星期一排程由節點1負責,星期二排程由節點2負責,依此類推。優點是鎖不需實體儲存媒體,缺點是不支持高可用、自解鎖。
- 唯一性索引分散式鎖:實作依賴於資料庫的唯一性索引。
- 假設有一排程需每天執行,有一表lock(date, uuid)其中date為PK。
- 當到達定時任務執行時間時,各個節點各自生成一筆記錄,並將其寫入資料庫的lock表中。由於date為主鍵擁有唯一性約束,所以最終只有一個節點寫入成功。
- 寫入之後,節點透過date屬性讀出這筆記錄,並與自身生成的uuid進行比較。如果資料庫中的uuid和自身生成的uuid一致,則說明是該節點寫入成功,獲得執行任務的許可權,否則說明該節點在執行許可權的搶奪中失敗,不能執行定時任務。
- 有一些資料庫支援記錄的TTL設定,我們可以透過為記錄設定TTL來實現自解鎖功能。當節點存活時,每隔一段時間會去資料庫延長自身持有鎖的TTL。一旦節點當機,記錄則會在到達TTL 後被資料庫刪除。如果資料庫不支援記錄的TTL設定,那麼必要時可以單獨設計一個TTL服務以協助資料庫完成TTL功能。
- 這種分散式鎖的設計依賴資料庫的唯一索引,保證了分散式鎖的唯一性。
- 唯一性驗證分散式鎖:
- 該鎖需要包含三個屬性:交易編號,在這裡是指date、鎖對應的uuid、鎖對應的建立時間,該時間由鎖媒體生成。
- 整個分散式鎖的執行演算法如下:
- 節點向鎖媒體中寫入一個鎖。寫入鎖時,由節點列出交易編號、生成uuid, 由鎖媒體列出鎖的建立時閒。如果發現鎖媒體中巳絰存在該交易的鎖,則直接認定自身在此次執行許可權的搶奪中失敗,放棄後續的操作。
- 節點向鎖媒體讀取當前交易編號下所有的鎖。
- 節點對讀取到的鎖按照時間排序,取時間最早的。如果出現時間並列的情況則再取uuid最小的。
- 節點用自身寫入鎖時生成的uuid驗證步驟3中取出的鎖,如果鎖的uuid和自身寫入鎖時生成的一致,則表示該節點獲取到了鎖;不然該節點在此次執行許可權搶奪中失敗。
- 透過鎖媒體列出的全域時間和uuid共同確認出了唯一一個有效的分散式鎖。
- 一致性分散式鎖:
- 在分散式系統中建立分散式鎖,該鎖在物理媒體上是分散式的,在邏輯上是唯一的。
- 分散式鎖的分散式系統必須支援全域事件排序,即滿足atomic consistency(線性一致性)。
- 例如:redlock。
第6章:分散式交易
- 應用內多資料庫交易方案:書中使用transaction的annotation將兩個db連線的操作包起來,但我個人是有疑慮。
- 單體應用間交易方案:
- 化為本地交易:以業務維度切領域導致模組化過細,但如果以功能維度來切可能更合理。例如績效應用與薪水應用可以合併成核算應用。
- 化為應用內多資料庫交易:如上,A應用使用了A資料庫,B應用使用了B資料庫。需要跨A及B資料庫的應用則放在C應用,同時連接兩個資料庫變成應用內多資料庫交易。
- TCC(Try-Confirm-Cancel):
- 在初始狀態和結束狀態之間引入一個新的暫存狀態,從而將從初始狀態到結束狀態的一步操作拆解為從初始狀態到暫存狀態的try操作、從暫存狀態到結束狀態的confirm操作、從暫存狀態到初始狀態的cancel 操作,類似state machine與2 phase commit。
- Try階段:
- 協調者呼叫各個分散式服務的交易進行運算,分散式服務的交易將此筆記錄的狀態更改為處理中,並將運算完後的結果儲存在暫存欄位形成暫存狀態,與2 phase commit的prepare階段類似。此時由於是暫存欄位,所以對於其他人進行讀取都還是可以讀取到舊值,不會阻塞併發。
- 覆蓋風險點:Try階段應該完成所有檢查與所有核心運算,盡可能覆蓋所有會失敗的風險,避免發生之後要confirm或cancel時才噴錯。
- 成敗可判定:Try階段在最後做完後要必需可以判斷成功或失敗,即接下來對此服務的交易來說應該要走confirm還是cancel流程。
- 可回復:由於有可能其他服務失敗導致要回復,因此Try階段的操作必須是暫存狀態的形式,以便rollback。
- Confirm階段:
- 當協調者收到所有分散式服務成功執行完Try階段後,協調者會對所有分散式服務告知進入Confirm階段。此時每個分散式服務會將剛剛的暫存狀態apply至自身上,並且將剛剛該筆記錄的狀態從處理中改成已處理。
- 高成功率:Confirm階段必須是高成功率的,如果此階段異常,只能透過外部查log的方式進行補償,因為其他服務已經apply暫存態至自身上了,不會在此階段執行回復。
- 成敗可判定:每個分散式服務的Confirm階段的結果將決定整個分散式交易的成功與否,所以其結果是需要可以判斷的。
- Cancel階段:
- 當協調者收到所有分散式服務執行完Try階段後,如果有任一一個服務無法完成Try階段或返回不成功,則協調者會對所有分散式服務告知進入Cancel階段。所有分散式服務會將剛剛該筆記錄的狀態從處理中改成已處理,並且刪除暫存狀態。
- 高成功率:Cancel階段也必須是高成功率的,如果此階段異常,代表該服務的回復是不成功的,此時整個分散式系統處於一個不確定的狀態中,因此也需要透過外部查log的方式進行補償。
- 成敗可判定:每個分散式服務的Cancel階段的結果將決定整個分散式交易的成功與否,所以其結果是需要可以判斷的。
- 實際應用:
- Try階段:建立一個不可見的訂單(佔用訂單號)。
- Confirm階段:使該訂單可見。
- Cancel階段:刪除此不可見的訂單。
- 本地非同步訊息機制:
- 同步的方式會導致如果一個分散式服務掉線,則會讓整個交易阻塞。如果對於時效性沒有嚴格的要求並且允許時間差,則可以使用本地非同步訊息機制。
- 協調者開啟交易後先完成自身的部分,並且發起訊息至本地的訊息中心,當訊息成功寫入後則返回呼叫端成功並且提交交易。各個分散式服務當收到訊息後則開始跑獨自負責的交易,如果失敗的話則重複retry至成功為止。當分散式服務完成獨自所屬的交易後會向協調者刪除協調者本地訊息中心所屬的任務。如此一來只要看協調者本地訊息中心剩餘的訊息即可知道有哪些交易還未被成功處理。
- 書中沒有說到如果一直失敗的case該怎麼處理。
- 非同步訊息中心機制:
- 非同步的方式也可以導入MQ來協助交易。協調者發起一個交易的訊息至MQ,各個分散式服務可以消費同個訊息並且非同步地完成交易,如果失敗的話則重複retry至成功為止。
- 書中沒有說到如果一直失敗的case該怎麼處理。
- 近似交易:
- 剛剛上面的交易都是可以判斷成功與否並且支持回復的,如果今天服務會執行的請求無法判斷成功與否,或是無法回復的,例如刪除檔案、重新啟動、發送郵件等等無法滿足ACID,則這類操作叫做近似交易。在服務沒有異常的情況下他們有著與交易類似的表現,因此還是可以當成交易對待。
- 以下是將操作分類的方法:
類別 是否對系統有影響 是否可判定成敗 是否可回復 舉例 A N – – 查詢類操作 B Y Y Y 向DB插入或更新資料 C Y Y N 刪除檔案 D Y N N 發送郵件、觸發無回應的系統 -
A、B類操作:使用資料庫內建的交易,支持ACID,是真正的交易。
- C類操作:這類操作只要失敗就無法回復至交易前的狀態。由於可以判定成敗,因此可以當成近似交易處理。
- D類操作:無法實現交易,也無法實現近似交易。
- 組建近似交易時,近似交易中可以包含多個A類、B類操作,且執行位置隨意,但是只能包含一個C類操作,並且只能在交易的最後一項操作。假如真的很不幸C類操作無回應導致A類、B類操作被回復了,後來才發現C類操作其實是成功的,此情況只能透過人工處理。
- 近似交易的處理原則是先做可回復的A類、B類操作,最後才做C類操作,盡量減少C類操作壞掉的可能。
第7章:服務發現與服務呼叫
- 服務發現
- 反向代理:所有請求都往代理節點送,代理再dispatch至背後的cluster。
- 註冊中心:類似DNS的概念,發請求前先去問註冊中心服務的位址在哪,問到後在發請求給該服務。
- 服務網格:在每個節點上加入sidecar,由sidecar與control plane溝通決定每個服務domain對於該節點應該使用的位址,之後打domain後及轉至對應服務。目前這個techstack的專有名詞叫service mesh,比較著名的產品是istio。
- 服務呼叫
- 以介面為基礎的呼叫:例如RESTful API,只要知道介面(API)格式與呼叫位址即可呼叫。
- 遠端程式呼叫:RPC,使用介面檔進行呼叫,剩下服務發現等功能由RPC框架底層實作。RPC框架根據介面檔生成實作空介面的動態代理,於是對此代理呼叫等於對遠端的程式進行呼叫。
- RPC通常實作使用OSI第四層TCP/UDP,序列化/反序列化由RPC框架做掉。相比之下HTTP是基於第七層,多了幾層的封裝加上資訊佔比低,因此RPC的效率較好。
第8章:服務保護與服務閘道
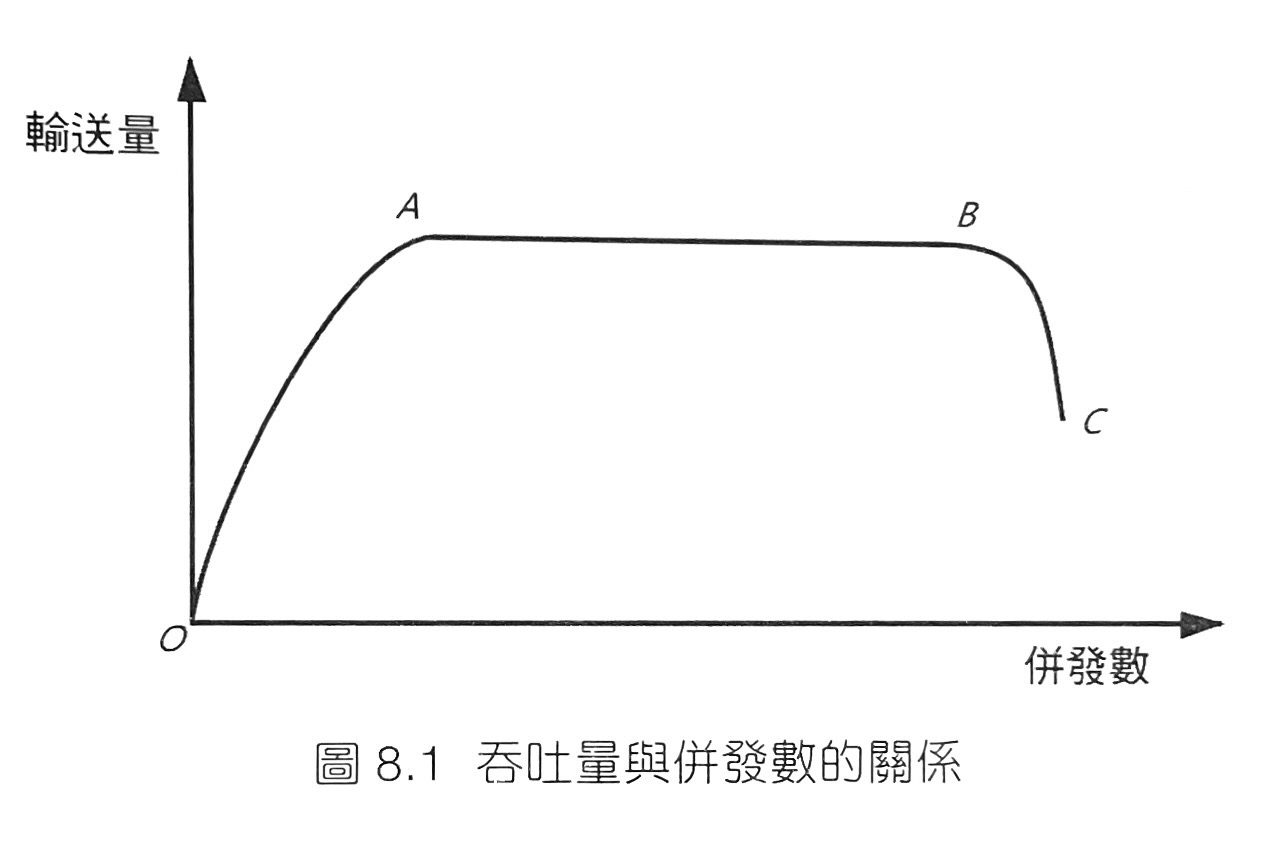
- 軟體中併發數與吞吐量是互相影響的。在OA段,系統的性能閒置,如果併發數增加,系統性能會進一步發揮,從而引發吞吐量增加。在AB段,系統的性能已經得到全部的發揮,此時無論併發數如何增加,系統總保持最大吞吐量不變,在這個區段內,系統也是穩定的。在BC段,過量的併發導致請求堆積,也因為CPU要有額外的overhead去處理buffer,導致context switch變多進而導致吞吐量開始下降,此時系統是不穩定的。
- 服務保護的手段:
- 隔離:為每個下層請求設定connection pool,當發至下一層的請求都沒回來(極有可能死了),則因為connection pool連線用盡,不讓開新請求,進而保護自身服務的系統資源。
- 限流:leaky bucket algorithm、token bucket algorithm。
- 降級:在尖峰時期暫時關閉不重要的服務,讓所有資源都去服務高併發請求。
- 熔斷:circuit breaker pattern。
- 恢復:當服務在上述保護措施開啟後又正常則需逐步恢復服務,類似緩存預熱的概念,不能一步就全部恢復,否則有可能又被打趴。
- 服務閘道:
- 微服務架構中,每個節點都可以對外服務,導致接口混亂分散不適合管理。
- 可以在系統中加入閘道,讓所有請求都需經過閘道,這樣閘道可以做到權限驗證、監控統計、HTTP轉RPC、服務保護等等功能。
第9章:冪等
- 不管函式被呼叫一或多次,他輸出的結果以及對整體系統狀態的影響應當一致。
- 插入冪等化:有PK,加上使用
INSERT ... ON DUPLICATE KEY UPDATE id = id。 - 更新操作冪等化:使用資料版本,例如:
UPDATE ... SET quota = quota - 1, version = version + 1 WHERE id = ? AND version = ?。 - 攔截重試呼叫:對於每個請求帶上訂單號、請求的uuid等等的,如果系統收到請求後發現訂單號、uuid是從未見過的則放行,如果發現是已呼叫過的請求則攔截。邏輯類似golang的
sync.Once()。
總結
這是我讀的第一本有關分散式系統的書籍,收穫不少,也建立了對分散式系統全盤的基礎。希望帶著這些觀念在開發上可以少走一些冤望路及少踩一些坑XD,也希望本篇筆記的內容有幫助到大家,謝謝收看~~