最近接到一個需求,需要將game record服務保存遊戲數據至資料庫的行為換成由game server直接推到message queue(我們用Kafka),再由consumer(worker)去寫入資料庫以實現與game record服務解耦。這樣的話同時就可以再創其他consumer group共用同份message去做其他運算。但是我們又不想再自己寫新的consumer,於是就把腦筋動到Kafka自帶的Kafka Connect上。
Kafka Connect是Kafka自帶的consumer框架,對於一些簡單的搬資料操作例如Kafka的message搬至MySQL、MongoDB、Elastic Search等等的可以委託Kafka Connect達成,就不用再自己寫consumer邏輯多啟一個服務。
在研究與嘗試了幾天後,本篇會記錄如何快速架起Kafka及Kafka Connect的過程。為了demo上的方便,本篇所啟的服務都是單台並且replication factor=1模式,實際在production時請依照所需適時增加replica set。
目錄
第1章:安裝Java
整套Kafka是由Java編寫而成的,所以我們要使用Kafka前必須安裝Kafka最低要求的Java 8。由於我們公司還在使用CentOS,其對應的安裝指令是: yum install java-1.8.0-openjdk。如果是其他系統就自行尋找對應的package manager的安裝方式。
第2章:Kafka下載、設定、啟動服務
準備好Java後,我們來將Kafka啟起來吧。首先至Kafka官網(https://kafka.apache.org/quickstart)找到最新版本的Kafka下載,截至本篇文章為止時版本為3.3.1。
下載好後解壓縮壓縮檔: tar -xzf kafka_2.13-3.3.1.tgz,並且切換目錄至Kafka資料夾下: cd ./kafka_2.13-3.3.1/。
接下來要編輯一下Kafka的設定檔: vim ./config/server.properties,設定Kafka對外允許連線的IP以及broker廣播的IP。
listeners=PLAINTEXT://0.0.0.0:9092(允許所有連線來源)。advertised.listeners=PLAINTEXT://192.168.1.5:9092(host自設,沒有網域用IP也行,用於讓Zookeeper廣播做節點發現用)。
新增Zookeeper的啟動script: vim START_ZOO_KEEPER.sh,並將以下內容寫入。
#!/bin/bash nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
新增Kafka的啟動script: vim START_KAFKA_BROKER.sh,並將以下內容寫入。
#!/bin/bash nohup bin/kafka-server-start.sh config/server.properties &
將啟動script設定為可執行: chmod +x START_KAFKA_BROKER.sh START_KAFKA_BROKER.sh。
啟動Zookeeper與Kafka: ./START_ZOO_KEEPER.sh、./START_KAFKA_BROKER.sh。
到這邊Kafka已經設定並且啟動成功了,看一下./nohup.out裡面的log應該是無異常正常執行的狀態。
第3章:Kafka Connect與Kafka MongoDB Sink Connector
現在,我們要來設定Kafka自帶的Kafka Connect,讓他為我們自動將Kafka的message搬至MongoDB去。不過由於Kafka Connect只是個空空的consumer框架,我們還要再載一個MongoDB官方推出叫Kafka MongoDB Sink Connector的插件,如此一來Kafka Connect才知道如何與MongoDB溝通從Kafka搬資料至MongoDB。
下載Kafka MongoDB Sink Connector
首先至Confluent官網(https://www.confluent.io/hub/mongodb/kafka-connect-mongodb)找到最新版本的MongoDB Sink Connector下載,截至本篇文章為止時版本為1.8.1。
下載好後解壓縮壓縮檔: unzip mongodb-kafka-connect-mongodb-1.8.1.zip,並將插件複製進Kafka的libs/資料夾內: cp mongodb-kafka-connect-mongodb-1.8.1/lib/mongo-kafka-connect-1.8.1-confluent.jar libs/。
Kafka Connect設定、啟動服務
接下來也要編輯一下Kafka Connect的設定檔: vim ./config/connect-distributed.properties,一樣也是設定對外允許連線的IP以及會被廣播的IP。
listeners=HTTP://0.0.0.0:8083(允許所有連線來源)。rest.advertised.host.name=192.168.1.5(host自設,沒有網域用IP也行,用於讓Zookeeper廣播做節點發現用)。plugin.path=libs/(指定Kafka Connect尋找插件的目錄,也就是我們剛剛複製過去的地方)。
新增Kafka Connect的啟動scriptvim START_KAFKA_CONNECT.sh,並將以下內容寫入。
#!/bin/bash nohup bin/connect-distributed.sh config/connect-distributed.properties &
將啟動script設定為可執行: chmod +x START_KAFKA_CONNECT.sh。
啟動Kafka Connect: ./START_KAFKA_CONNECT.sh。
最後看一下./nohup.out裡面的log應該可以看到Kafka Connect也起來了。
在Kafka Connect上設定啟用Kafka MongoDB Sink Connector
最後一個階段了,現在萬事俱備只欠東風。我們要在Kafka Connect上啟用Kafka MongoDB Sink Connector,並且設定告訴Kafka Connect要從哪個topic同步message至哪個MongoDB的collection。
我們先打API看看Kafka Connect是否正常載入Kafka MongoDB Sink Connector插件。
GET http://192.168.1.5:8083/connector-plugins
得到API回應:
[
{
"class": "com.mongodb.kafka.connect.MongoSinkConnector",
"type": "sink",
"version": "1.8.1"
},
...
]
正常,插件陣列有出現MongoSinkConnector代表有正確被Kafka Connect辨識到。接下來我們要來告訴Kafka Connect同步的來源及目的地。
POST http://192.168.1.5:8083/connectors
Body:
{
"name": "kafka-mongo-game-record-sync",
"config": {
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"topics": "game_record",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"connection.uri": "mongodb://192.168.1.5:27017/",
"database": "game_record",
"namespace.mapper": "com.mongodb.kafka.connect.sink.namespace.mapping.FieldPathNamespaceMapper",
"namespace.mapper.value.collection.field": "gameType"
}
}
- 第
5行設定了Kafka的來源topic,這邊我們設定從game_record來。 - 第
9行設定了MongoDB目的地的連線資訊。 - 第
10行設定了MongoDB目的地使用的DB,這邊我們也是設定與Kafka的topic同名的game_recordDB。 - 第
12行設定了Kafka Connect會根據message裡面的gameType欄位,決定歸檔至MongoDB裡面game_record這個DB底下對應的collection內。
來打API看看是否新增成功:
GET http://192.168.1.5:8083/connectors/kafka-mongo-game-record-sync/status
得到API回應:
{
"name": "kafka-mongo-game-record-sync",
"connector": {
"state": "RUNNING",
"worker_id": "192.168.1.5:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "192.168.1.5:8083"
}
],
"type": "sink"
}
看起來沒問題,還有以下其他可使用的Kafka Connect API也可以玩玩看。
| Method | REST API | 說明 |
|---|---|---|
GET |
/connectors | 取得所有正在運作中的connector |
POST |
/connectors | 新增一個connector |
GET |
/connectors/{name}/ | 取得指定connector的資訊 |
GET |
/connectors/{name}/config | 取得指定connector的設定資訊 |
PUT |
/connectors/{name}/config | 修改指定connector的設定資訊 |
GET |
/connectors/{name}/status | 取得指定connector的運行狀態(運行中、停止、失敗),如果有發生錯誤,也會顯示具體的錯誤資訊 |
GET |
/connectors/{name}/tasks | 取得指定connector運行中的 task |
GET |
/connectors/{name}/tasks/{tasksId}/status | 取得指定connector指令的 task 狀態 |
PUT |
/connectors/{name}/pause | 暫停指定的connector和它的 task |
PUT |
/connectors/{name}/resume | 恢復一個暫停中的connector |
POST |
/connectors/{name}/restart | 重新啟動一個connector |
POST |
/connectors/{name}/tasks/{taskID}/restart | 重新啟動一個 task |
DELETE |
/connectors/{name}/ | 刪除一個 connector,停止它的所有 task 並且刪除相關 config |
到此,當game server(producer)推遊戲記錄(message)至game_record這個topic後,Kafka Connect將會自動consume剛剛的message並歸檔至MongoDB。我們來試驗看看吧。
我們隨便推一筆資料進Kafka,欄位隨意,但是必須給定gameType欄位,因為Kafka Connect會讀message裡面的gameType欄位決定對應的collection。
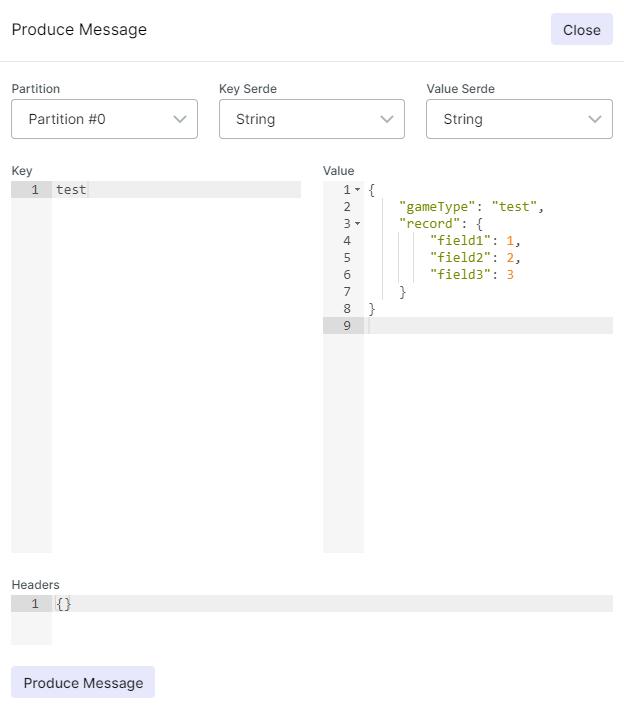
接著到MongoDB看看資料是不是同步過來了。
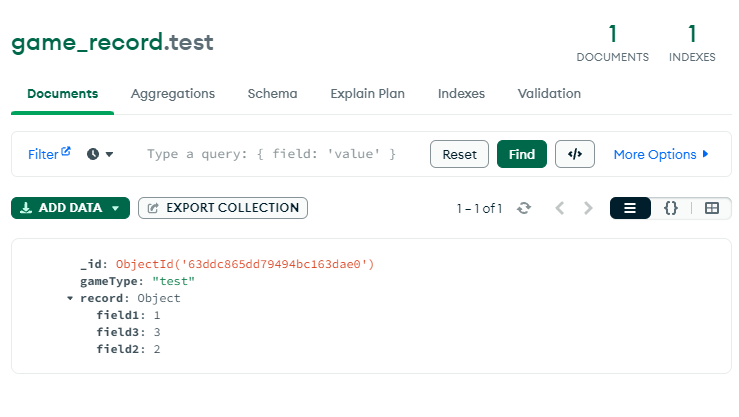
登愣,運作完全正常~現在我們已經與game record服務解耦,並且在不編寫任何一行consumer的code情形下,只要有人推新的message至Kafka,Kafka Connect就會自動同步一份至MongoDB了。日後如果有人也要接game record的數據來用就只要新增consumer group就可以共用同份message去做其他運算,實現一魚多吃。
參考資料
Kafka官方文件: https://kafka.apache.org/quickstart
Kafka官方的Kafka Connect文件: https://docs.confluent.io/platform/current/installation/configuration/connect/sink-connect-configs.html
MongoDB官方的Kafka MongoDB Sink Connector文件: https://www.mongodb.com/docs/kafka-connector/current/tutorials/sink-connector/