在 大學選課系統自動填入驗證碼 這篇介紹了如何利用驗證碼語音播放功能的bug來填入驗證碼
本篇就來實作看看利用近年來很熱門的卷積神經網路(CNN)學習並辨識驗證碼
驗證碼示意圖:

安裝所需的套件
在開始前我們會用到以下套件,這是我在寫本篇親測可正確執行的版本組合
MacOS 10.14.6
Python: 3.7.3
numpy: 1.18.0
scikit-learn: 0.22
TensorFlow: 2.0.0
Pillow: 6.2.1
如果有缺少的可以使用pip來安裝
NumPy: pip install numpy
scikit-learn: pip install scikit-learn
TensorFlow: pip install tensorflow
Pillow: pip install Pillow
準備訓練資料
搜集與預處理資料是整個建立模型前最重要且費時的工作
資料的好壞會很直接地影響模型的學習
為了不卡在這步太久,我已經先幫大家整理了100張驗證碼影像檔並存在training資料夾、5張訓練好後測試用的驗證碼影像檔存在testing資料夾
檔名就是該驗證碼所表示的6個數字,下載後直接解壓縮等等放在與程式碼同個資料夾下即可
建立與訓練模型
首先,建立一個名為train.py的檔案
並先將要使用的套件import進來
import numpy as np import os from sklearn.model_selection import train_test_split from tensorflow import keras from tensorflow.keras import layers from tensorflow.keras import models from tensorflow.keras.preprocessing.image import img_to_array from tensorflow.keras.preprocessing.image import load_img
初始化所需變數
epochs = 10 #訓練的次數 img_rows = None #驗證碼影像檔的高 img_cols = None #驗證碼影像檔的寬 digits_in_img = 6 #驗證碼影像檔中有幾位數 x_list = list() #存所有驗證碼數字影像檔的array y_list = list() #存所有的驗證碼數字影像檔array代表的正確數字 x_train = list() #存訓練用驗證碼數字影像檔的array y_train = list() #存訓練用驗證碼數字影像檔array代表的正確數字 x_test = list() #存測試用驗證碼數字影像檔的array y_test = list() #存測試用驗證碼數字影像檔array代表的正確數字
寫一個將驗證碼6位數獨立切出的funciton
驗證碼數字影像檔的array會存在x_list,驗證碼數字影像檔array代表的正確數字會存在y_list
def split_digits_in_img(img_array, x_list, y_list):
for i in range(digits_in_img):
step = img_cols // digits_in_img
x_list.append(img_array[:, i * step:(i + 1) * step] / 255)
y_list.append(img_filename[i])
從training資料夾以灰階的形式讀入所有.png的驗整碼,並逐一將6位數驗證碼影像檔切出
img_filenames = os.listdir('training')
for img_filename in img_filenames:
if '.png' not in img_filename:
continue
img = load_img('training/{0}'.format(img_filename), color_mode='grayscale')
img_array = img_to_array(img)
img_rows, img_cols, _ = img_array.shape
split_digits_in_img(img_array, x_list, y_list)
將y_list所存的驗證碼正確數字0-9轉成categorical形式
舉例: 1 = [0, 1, 0, 0, 0, 0, 0, 0, 0, 0,]、2 = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0,]、依此類推…
然後將所有的資料拆成訓練用及測試用資料集
y_list = keras.utils.to_categorical(y_list, num_classes=10) x_train, x_test, y_train, y_test = train_test_split(x_list, y_list)
接下來進入我們的model部分了,先判斷同個資料夾內有沒有cnn_model.h5這個檔案
如果有就代表曾經訓練過,將該模型存檔載入繼續訓練
如果沒有,則創一個新的模型,下圖是使用程式碼會建立的CNN模型結構
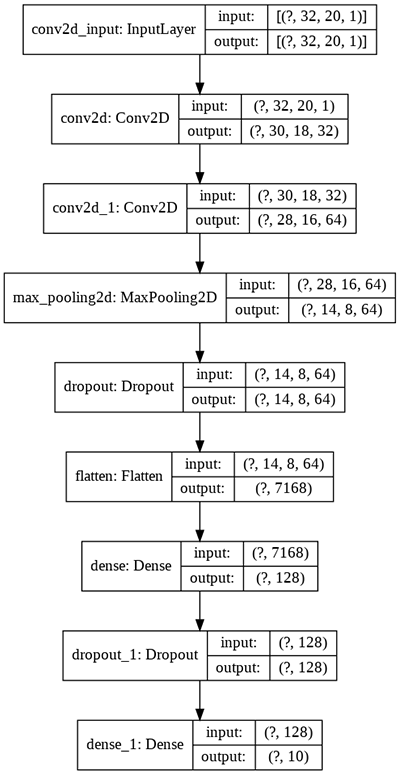
if os.path.isfile('cnn_model.h5'):
model = models.load_model('cnn_model.h5')
print('Model loaded from file.')
else:
model = models.Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(img_rows, img_cols // digits_in_img, 1)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(rate=0.25))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(rate=0.5))
model.add(layers.Dense(10, activation='softmax'))
print('New model created.')
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adam(), metrics=['accuracy'])
模型有了後,就可以進入訓練的部份了
由於模型不複雜,自己的經驗是用筆電CPU跑10個epoch大約半分鐘內可以跑完
當訓練跑完後,顯示一下準確率,並在無誤後存檔
model.fit(np.array(x_train), np.array(y_train), batch_size=digits_in_img, epochs=epochs, verbose=1, validation_data=(np.array(x_test), np.array(y_test)))
loss, accuracy = model.evaluate(np.array(x_test), np.array(y_test), verbose=0)
print('Test loss:', loss)
print('Test accuracy:', accuracy)
model.save('cnn_model.h5')
程式碼寫好後可以使用python train.py執行訓練
執行時可以看到訓練過程loss逐漸降低,accuracy準確率逐漸升高,最後測試資料集的準確率來到98%
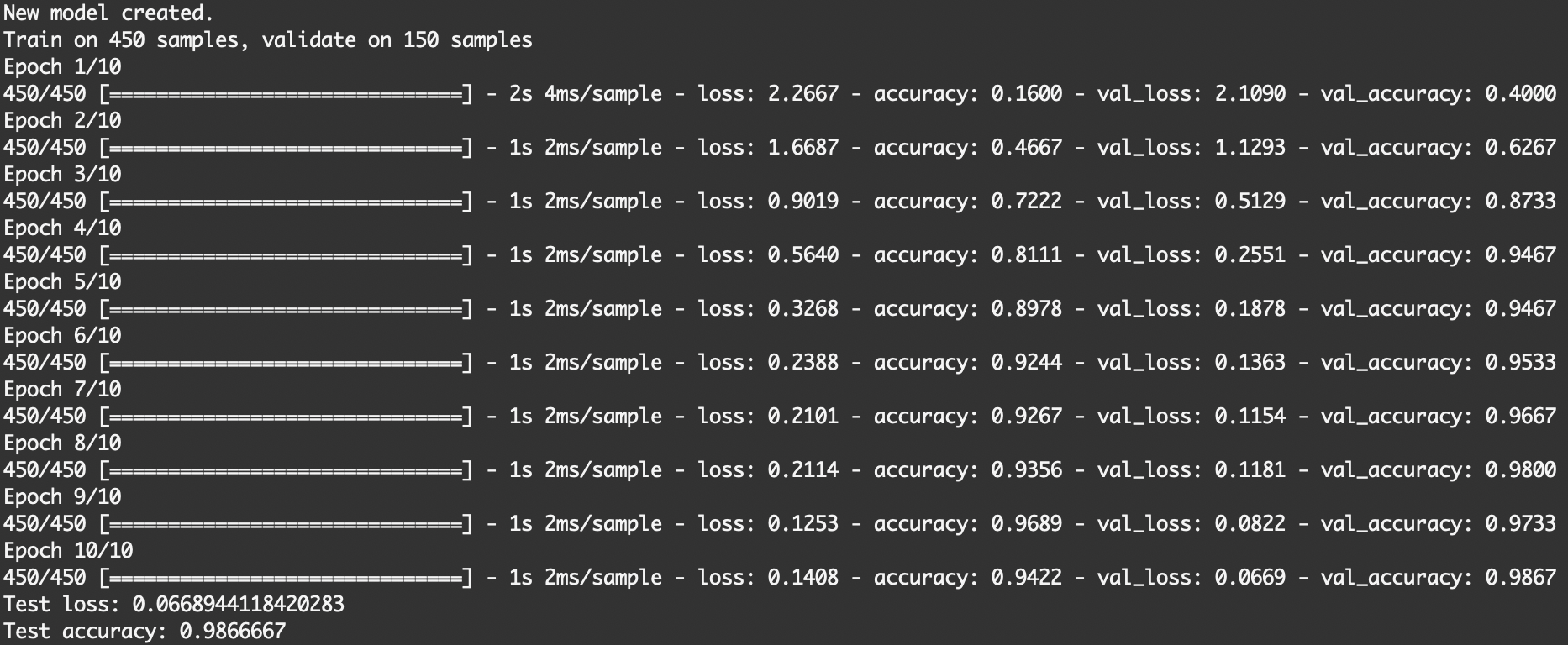
接下來我們將測試上面剛訓練好的模型:)
測試模型
這次,建立一個名為predict.py的檔案
並先將要使用的套件import進來
import numpy as np import os import sys from tensorflow.keras import models from tensorflow.keras.preprocessing.image import img_to_array from tensorflow.keras.preprocessing.image import load_img
初始化所需變數,以及將numpy設置只顯示至小數點下9位
img_rows = None
img_cols = None
digits_in_img = 6
model = None
np.set_printoptions(suppress=True, linewidth=150, precision=9, formatter={'float': '{: 0.9f}'.format})
跟train.py類似,寫一個將驗證碼6位數獨立切出的funciton
def split_digits_in_img(img_array):
x_list = list()
for i in range(digits_in_img):
step = img_cols // digits_in_img
x_list.append(img_array[:, i * step:(i + 1) * step] / 255)
return x_list
載入模型,如果找不到檔案就終止程式
if os.path.isfile('cnn_model.h5'):
model = models.load_model('cnn_model.h5')
else:
print('No trained model found.')
exit(-1)
提示使用者輸入檔名,並依輸入的檔名以灰階的形式載入驗整碼影像檔
載入後將驗整碼6碼獨立切出儲存至x_list
img_filename = input('Varification code img filename: ')
img = load_img(img_filename, color_mode='grayscale')
img_array = img_to_array(img)
img_rows, img_cols, _ = img_array.shape
x_list = split_digits_in_img(img_array)
接著依序將獨立切出的每一碼送進模型進行預測(其實也是可以一次預測整個batch啦:P)
varification_code = list()
for i in range(digits_in_img):
confidences = model.predict(np.array([x_list[i]]), verbose=0)
result_class = model.predict_classes(np.array([x_list[i]]), verbose=0)
varification_code.append(result_class[0])
print('Digit {0}: Confidence=> {1} Predict=> {2}'.format(i + 1, np.squeeze(confidences), np.squeeze(result_class)))
print('Predicted varification code:', varification_code)
程式碼到這裡結束
現在我們就可以使用testing資料夾裡面模型訓練時從沒看過的驗證碼影像進行測試啦
輸入python predict.py執行,接著再輸入要測試的影像檔名
整個預測結果就會像這樣,6碼都辨識正確呢^^

機器學習是不是很有趣呢:)
不好意思我在實作時,line 32: img = load_img(‘training/{0}’.format(img_filename), color_mode=’grayscale’) ,這行出現TypeError: load_img() got an unexpected keyword argument ‘color_mode’
請問你的tensorflow是什麼的版本呢?
1.10.0
但是後來我嘗試將 ‘color_mode’ 刪掉,是可以正確運行的,非常感謝你
by the way 45行
model.add(layers.Conv2D(32, kernel_size=(3, 3), activation=’relu’, input_shape=(img_rows, img_cols // digits_in_img, 1))) ,最後面的那個 1 應該是3 wwwwww
因為第37行讀影像時已經是灰階的格式讀入color_mode=’grayscale’
所以不是RGB三個值了,是只有一個值代表黑白
不好意思我在實作時,程式沒有任何錯誤,但在執行後,跑出這一串’numpy.ndarray’ object has no attribute ‘append’
請問我是哪裡出了問題?
第幾行呢?
因為numpy的array他的形狀都是初始化後即固定的
所以沒有.append()這種用法
有用到.append()的變數我上面都是用list型態
比較有可能是不小心把他轉型成numpy.ndarray了
然後下面再操作.append()就抱錯了
你好,請問可以訓練英數字嗎?
只要資料集夠多是可以的唷
您好,訓練英文和數字混雜的情況,請問有什麼參數必須變動?
我做的時候會出現這個錯誤,好像是英文字母的部份。謝謝。
invalid literal for int() with base 10
如果不要把字串轉成數字格式,數字跟英文一樣都直接當字串來處理看看呢。
Sorry, 我將英文字母與數字產生Map並將所有字元編列唯一數字,0~9 A-Z對應各數字,不知道這種操作是不是錯誤的,或是可提供一些修改部分建議。感謝!
還是有辦法貼出部分程式碼這樣比較好debug呢
另外想詢問大大,因目前突然開始接觸機器學習,但先備知識不足或已經遺失了,矩陣、線性、回歸等等,對於tensorflow的學習似乎有阻礙,想詢問一下學習途徑或該怎麼補齊,那些領域的知識為必備?
我自己會建議買書
找tensorflow+keras這種比較熱門的框架
書中有一步一步實作範例的書
先完整跟著書刻一遍程式
能訓練起來能動了 知道機器學習是怎麼個運作後
再去深入他所用的那些函式背後的數學理論
這樣的學習會比較有趣且知道為了什麼而學
我自己的經驗是在大學時k了微積分
當時學了這套工具學了運算技巧
但不知道對資工領域到底能拿去做什麼應用
直到又接觸了機器學習才有了感觸
哦~原來以前學的東西是這樣子被應用的呀~
之後又回去把微積分拿出來重要的地方又複習了一下
自己的經驗給你參考:)
看了Coursera的ML相關課程之後
經過了一個月的練習
終於達到單字可以8成的準確率
但因目標驗證碼有五碼 連續五碼的準確率就會降到大概3成左右
現在只能苦命補齊目標驗證碼的訓練資料看看能否提升
感謝樓主協助 我也要拿出微積分了 研究一下線代哈哈
不好意思,我想請問要怎麼對資料進行預處理,我也想實作驗證碼的辨識,我這邊已經下載了很多張的圖片,但不知道怎麼對資料進行label。
上面的範例我是將圖片對應的每個數字當作檔名
也有些人會特別寫在另一份檔案,裡面記錄每個檔案對應到的正確數字