
※ 綠色的是定位詞,藍色是選取的詞
以前我在parse html的element時都是用Substring()配IndexOf()
但每做一次Substring()就會想起以前老師講過string是一個object
每修改它一次其實就是new一個已修改過的object,這樣的做法在記憶體及效能上來說不太優
所以今天要來講如何用正則表達式(正規表示法),乾脆俐落地擷取到想要的字
※ 因為我實在想不到要怎麼用中文表示,正則表達式先找的到那個詞,再以它為基準向前或向後選取,所以使用”定位詞”一詞。希望大家不要太介意,能讓意思傳達給各位就好:P
Positive Lookbehind
顧名思義就是先找到定位詞,然後從定位詞尾端開始向後選取
語法:
(?<=...)
上面的”…”(不包含引號)請填定位詞
拿常見的html程式碼當例子
<input type="hidden" id="__VIEWSTATE" value="D399Lx95w212" />
假設今天__VIEWSTATE的value會根據每次瀏覽而改變,而且數字及英文大小寫沒有一定的位置,也沒有好用的library可以直接獲得tag value
我們的備案就會想從value=往後找雙引號內的所有東西
因此,正則表達式就可以寫成
(?<=(value=")).*"
value="用括號刮起來是為了讓正則表達式判斷成一個詞
.代表任意字元
*代表可以是0個或多個
"則是結尾的雙引號

如此一來就可以順利直接選到value了 (歡呼~
※ 綠色的是定位詞,藍色是選取的詞
這時眼尖的網友表示:咦~不對啊,那最後的雙引號怎辦?
沒錯,於是輪到第二個主題positive lookahead登場。
Positive Lookahead
類似positive lookbehind先找到定位詞,然後從定位詞最前端開始向前選取
語法:
(?=...)
上面的”…”(不包含引號)請填定位詞
繼續剛剛上面完成一半的例子,我們不想要最後面的雙引號
(?<=(value=")).*"
把最後面的雙引號先拿掉,兜成定位詞
(?=")
再加回去剛剛的表達式
(?<=(value=")).*(?=")
登愣,結果正是我們想要的value值。
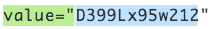
※ 綠色的是定位詞,藍色是選取的詞
額外補充
可以用 Regex101 這個網站先試試正則表達式的語法有沒有符合需求
對於更大的範圍還可以在前面加上id,指定要哪個id後的value
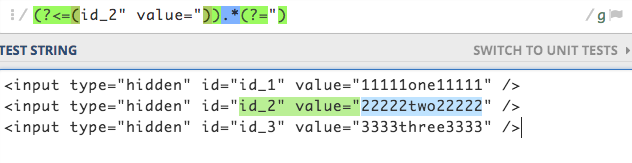
2018/10/14 謝謝網友raku的更正
應該是(?<=(value=")).*?(?=")
而不是(?<=(value=")).*(?=")
*是比對前一個規則零次至多次
這樣中間如果有雙引號也會被算進去,直到最後一個雙引號前止
應該改成*?來限制滿足越少次越好,才能保證最近的兩個雙引號成對
中間那段應該改用非貪婪的寫法「.*?」,否則若後面還有引號他會繼續匹配然後再去抓最後一個引號
已經修改了,謝謝你的更正^^